
所以,在寫了 40,000 多字關於 AI 安全有多奇怪和困難之後⋯⋯我對人類解決這個問題的機會感覺如何?
⋯⋯其實相當樂觀!
不,真的!
也許這只是自我安慰。但在我看來,如果這是所有問題的空間:

那麼:雖然沒有單一解決方案能覆蓋整個空間,但整個問題空間都被一個(或多個)有前景的解決方案覆蓋:
我們不需要一個完美的解決方案;我們可以疊加多個不完美的解決方案!這類似於風險分析中的瑞士乳酪模型——每一層防禦都有漏洞,但如果你有足夠多的層,漏洞在不同的位置,風險就無法一路穿過:
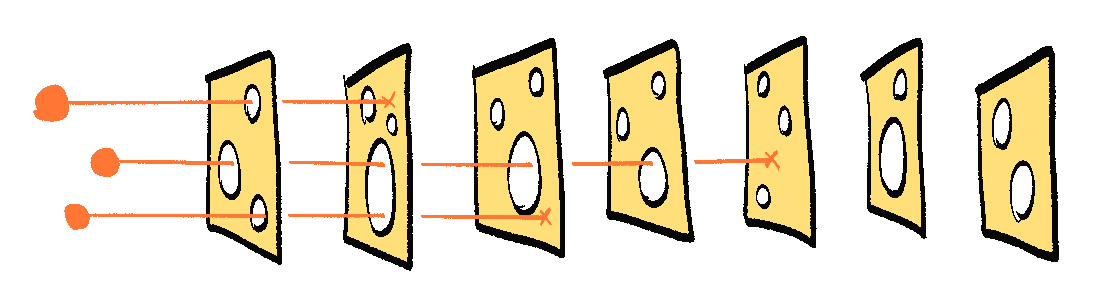
(: 🧀 附加章節:為什麼瑞士乳酪模型在 AI 安全領域中具有爭議 ← 選讀:每當你看到虛線底線的部分,都可以點選展開!)
這並不意味著 AI 安全已經 100% 解決——我們仍然需要反覆檢查這些提案,並讓工程師/政策制定者知道這些解決方案,更不用說實施它們了。但目前,我會說:「還有很多工作要做,但有很多有前景的開始」!
作為提醒,這是我們如何分解 AI 和 AI 安全的主要問題:
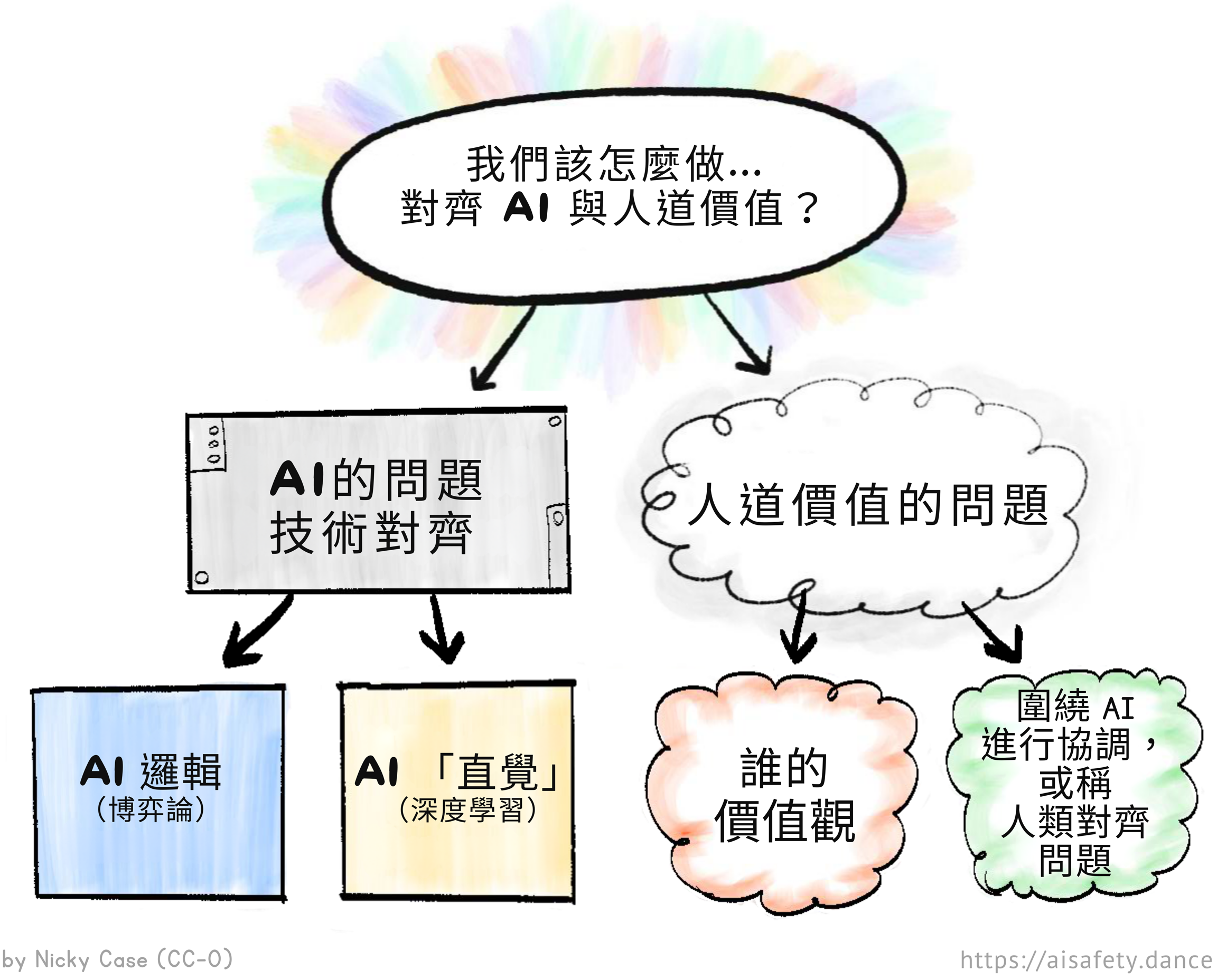
所以在這第三章,我們將學習每個問題部分最有前景的解決方案,同時誠實地討論它們的優點、缺點和未知數:
🤖 AI 中的問題:
- 可擴展監督:即使 AI 比我們先進得多,我們如何安全地檢查它們?↪
- 解決 AI 邏輯:AI 應該以我們的「未來生活」為目標 ↪,並以不確定性學習我們的價值觀 ↪。
- 解決 AI「直覺」:AI 應該易於「讀寫」↪,具有穩健性 ↪,並以因果關係思考。↪
😬 人類中的問題:
🌀 繞過問題:
(如果你想跳著看, 目錄在你右邊!👉 你也可以
目錄在你右邊!👉 你也可以  改變這頁的樣式,以及
改變這頁的樣式,以及  看看還剩多少閱讀量。)
看看還剩多少閱讀量。)
順便說一下:這個最終的第三章,於 2025 年 12 月發布,本應在 12 個月前發布。但由於一堆我不想細說的個人事情,我被耽擱了。抱歉讓你們等了一年才等到這個結局!好處是,從那時起這個領域有了很多進展和研究,所以我很興奮能與你們分享這一切。
好的,讓我們開始吧!不需要更多介紹,或關於牛仔貓男的奇怪故事,讓我們直接——
:x Swiss Cheese
風險分析中著名的瑞士乳酪模型告訴我們:你不需要一個完美的解決方案,你可以疊加多個不完美的解決方案。
這個模型被用於每一個安全至關重要的領域,從航空到網路安全到疫情防護。一個不完美的解決方案有「漏洞」,很容易被穿透。但疊加足夠多的層,漏洞在不同的地方,就幾乎不可能被繞過。
然而,瑞士乳酪模型在 AI 安全領域內特別具有爭議性。所以,讓我們來探討幾個批評:
1. 有人說瑞士乳酪模型不適用於智慧型對手。例如,這裏是機器智慧研究院 (MIRI) 的 Nate Soares 的話:
「如果你製造了某個試圖到達你所有瑞士乳酪另一邊的東西,它只需要穿過這些洞就不是那麼難。」
我會回應:「這是一個比喻,而非同構(isomorphism)。」瑞士乳酪模型經常在網路安全中被使用,而我們在那裡經常需要防範比我們更強大的對手。例如:藉由強大且唯一的密碼 + 多重身分驗證 + 基本的反詐騙意識 = 一個普羅大眾也能防範更強大的網路罪犯。
但是,對於瑞士乳酪模型還有一個更強烈的批評,它適用於超級智慧 AI:
2. 瑞士乳酪模型只有在防禦的每一層沒有共同的單一漏洞時才有效。然而,如果你嘗試「防範所有你能想到的風險」的策略,那麼就有一個共同的漏洞:這些防禦只能防範你所能想到的風險。但根據定義,一個比人類更聰明的 AI 將能夠識別出我們想不到的風險。
一個比喻:如果我這個西洋棋新手試圖與世界冠軍馬格努斯·卡爾森(Magnus Carlsen)對弈,那麼「防範所有我能想到的攻擊」肯定會失敗,因為馬格努斯能想到我想不到的攻擊。(感謝 Robert Miles 提供這個比喻。)另一個比喻:我這個網路安全新手可以防範大多數普通的網路罪犯,但如果我被國家級的行為者特別針對,他們可以執行我甚至無法理解的駭客手段。
總結來說:瑞士乳酪模型只有在防範比你稍微先進、但不是遠遠先進許多的對手時才有效。
即便如此,情況並非毫無希望。有兩種方法可以解決這個問題:
一種是可擴展監督(Scalable Oversight)(我們稍後將在網頁中更詳細地介紹)。如果我可以驗證一個只比我聰明 10% 的 AI,那麼我就可以使用那個 AI 來協助我驗證一個比我聰明 20% 的 AI,接著使用它來協助我驗證一個聰明 30% 的 AI,以此類推,直到達到任意水準的 AI。這種策略在有限的環境下已經行之有效:我們已經設計出可以數學驗證更大程式正確性的程式。(不過,目前我們能驗證的程式類型仍然有限。)
另一種(互補的)策略是「乾脆」從一開始就避免製造一個對手。這並非易事——因為古德哈特定律,幾乎你程式設定 AI 去最大化的任何指標或分數,
- 💖➡️💖 遞迴獎勵建模 (Recursive Reward Modeling):使用第 N 層機器人不僅在事後檢查與控制第 (N+1) 層機器人,而是首先訓練它內在的「目標和慾望」。具體而言,每個機器人會協助你訓練下一個機器人。(詳細細節:[1])正如 AI 研究員 Jan Leike 所說:「不要試圖監禁一個怪物,而是建造一些你真正可以信任的東西!」
- 這也有助於防止價值漂移(value drift),以防「價值是脆弱的(value is fragile)」。在預設情況下,如果你將你的價值觀傳遞給第一個機器人,而它試圖將其傳遞給第二個,依此類推,就像傳話遊戲一樣,第 N 個機器人最終會得到一個扭曲的價值觀。但在遞迴獎勵建模中,每個機器人都會直接協助你訓練下一個機器人。因此,機器人的能力越強,它就能越好地學習你的價值觀!
- 📈 可擴展監督的縮放定律 (Scaling Laws For Scalable Oversight):定量測量你需要多少監督層級/步驟來最大化監督成功。令人鼓舞的是,就像先前關於你給 AI 餵更多計算資源時它如何改進的「縮放定律」一樣,這些「可擴展監督的縮放定律」似乎也是可預測且可測量的。Terekhov & Liu 等人 2025 更進一步,計算了各種 AI 攻擊者和防禦者的「控制稅」(以美元計)。
- 🕵️🦹 GPT-3.5 可以捕捉由更強大的 GPT-4 編寫的狡猾、微妙有害的程式碼。
- 🕵️🥷 證明者-驗證者遊戲 (Prover-Verifier Games):讓一個弱小的「數學證明驗證者」AI 對抗兩個更強的 AI:一個「有幫助的證明者」給出真實的證明,和一個「狡猾的證明者」給出看起來真實的假證明。在這個遊戲上訓練的結果:弱驗證者可以變得足夠好來區分真假證明,但強狡猾證明者長期無法獲勝。不錯!
- 🪜 弱到強泛化 (Weak-to-Strong Generalization):發現 GPT-2 在監督和訓練 GPT-4 方面做得相當不錯。(一個比它大好幾個數量級的 AI)
- 💬💬 辯論 (Debate):略有不同。不是讓較弱的 AI 監督較強的 AI,辯論讓 2 個同等強大的 AI 互相辯論,拆解彼此的邏輯。只要真理比謬誤更能經受審視,真理就會獲勝。(好吧,也許。[2])
- ☕️ 超級過濾 (Superfiltering):使用一個小型開源 AI 來過濾用於訓練更大 AI 的資料!這可以幫助確保更大的 AI 不僅在高質量寫作上訓練(而不是網頁上的垃圾貼文),而且不會學習如何越獄它自己或它的監督者,學習在評估基準上作弊的答案,或學習像炸彈和生物武器製造這樣的危險能力。
- (嚴格來說不是監督,但它仍然是一種迭代的、可擴展的方法!)
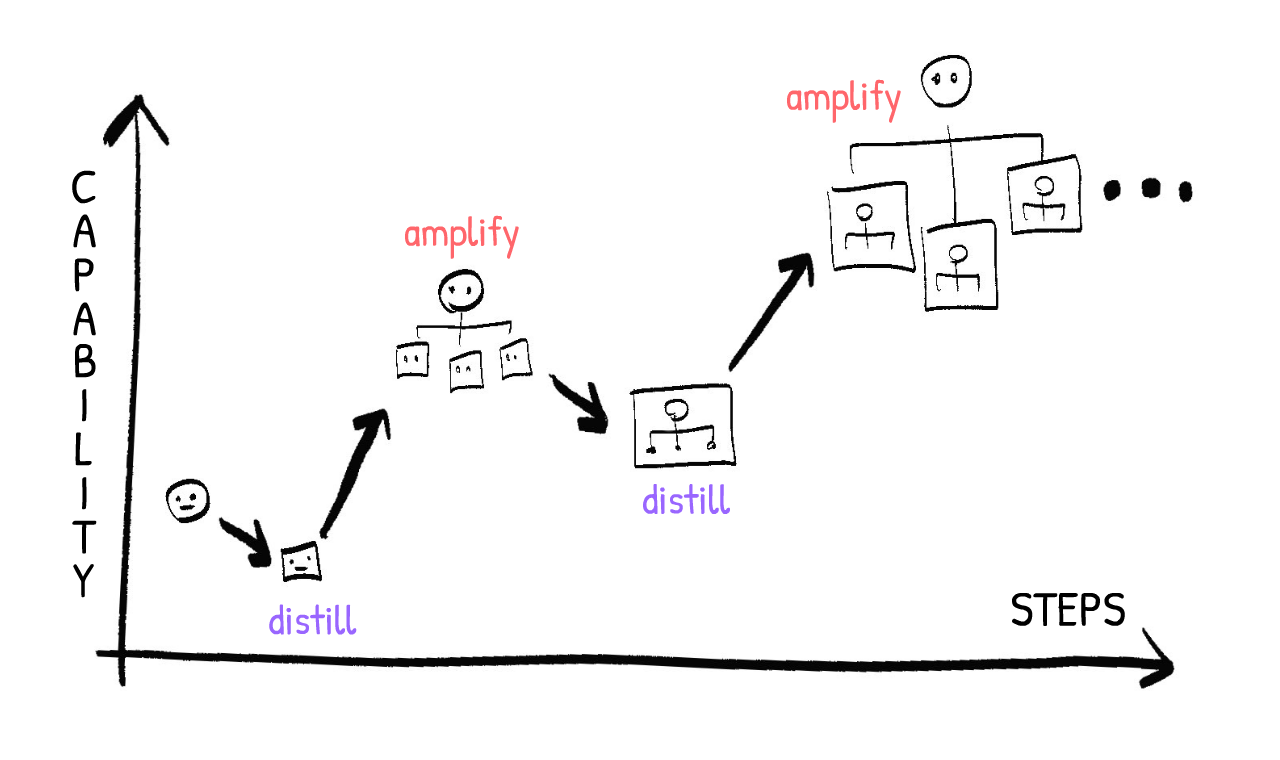
- 👯♀️ 迭代蒸餾與放大 (Iterated Distillation & Amplification, IDA):更安全——不是監督比你稍聰明的 AI,而是監督嚴格比你弱的 AI。那麼,這種設定如何能給你超人智慧?非常粗略地總結:在 IDA 中,你成為一個由訓練來模仿你的 AI 組成的組織的 CEO!由於每個 AI 都模仿你,而你是整個系統的 CEO,系統作為一個整體與你的價值觀對齊——同時也放大你的能力。
- 🤓 形式化驗證 (Formal Verification):這實際上早於現代 AI。通常在程式設計中,我們藉由嘗試一堆輸入來測試程式碼,但總有可能漏掉某個會導致 Bug 的輸入。因此,在形式化驗證中,我們對程式在所有可能輸入下的運作進行數學證明。這與可擴展監督的關聯:我們可以(而且已經!)設計小型程式來協助人類驗證更大程式的可信度![3]
不過,保持健康的批判態度是好的。這裡是一些來自監控大型語言模型(LLM)如 ChatGPT 和 Claude 的最近「令人沮喪」的發現:如果你用一個能讀取其思維鏈的監控器太努力地訓練一個 LLM,它會學會甚至在它自己的「思想」中隱藏它的邪惡計劃。(Baker & Huizinga 2025)。而且,給定天真的監督技術,LLM 實際上很容易越獄它的監控器,因為 LLM 已經存在足夠長的時間,關於越獄的資訊就在它們自己的訓練資料中。(Terekhov, Panfilov & Dzenhaliou 2025)
但即使這些監督方法失敗,仍然有很多其他的!(正如我們將在後面的可解釋性和引導章節中看到的)。總的來說,我仍然樂觀。再說一次:我們不需要一個完美的解決方案,我們可以疊加很多不完美的解決方案。
所以:如果我們能對齊一個比我們稍聰明的 AI,那麼,透過可擴展監督,我們可以對齊遠更先進的 AI。
⋯⋯但現在,我們甚至無法對齊比我們笨的 AI。
這就是接下來幾個提議的解決方案旨在解決的問題!但首先⋯⋯
:x Robust Chain Math
首先,我們做一個假設,即監督者的失敗在各層級是相同的且彼此完全獨立。然而,只要失敗不是 100% 相關的,你可以修改下面的數學,這個論點的精神仍然成立。
總之:假設我們每層有 $k$ 個監督者,我們有 $N$ 層。也就是說,鏈條有 $N$ 個環節長,$k$ 個環節寬。假設任何監督者失敗的機率是 $p$,它們都是獨立/不相關的。
如果任何一層失敗,鏈條就失敗。但是!一層只有在所有並行監督者都失敗時才會失敗。
一層中所有並行監督者都失敗的機率是 $p^k$。
為方便起見,讓我們把一層不失敗的機率稱為 $q$。$q = 1 - p^k$
任何一層失敗的機率,是 1 減去沒有任何一層失敗的機率。$N$ 層都不失敗的機率是 $q^N$。所以,任何一層失敗的機率是 $1 - q^N$。代入 $q = 1 - p^k$,這意味著沒有任何一層失敗,我們的可擴展監督方案成功的機率是 $1 - (1-p^k)^N$。我們有了公式!🎉
現在,代入上面例子的數值,失敗機率 $p = 0.05$,鏈條有 $N = 20$ 層深,那麼失敗的機率是⋯⋯
- 對貼於 $k=1$ 條鏈:$1 - (1-0.05^1)^{20} \approx 0.64 \approx 64%$
- 對於 $k = 2$ 條編織鏈:$1 - (1-0.05^2)^{20} \approx 0.049 \approx 5%$
- 對於 $k = 3$ 條編織鏈:$1 - (1-0.05^3)^{20} \approx 0.0025 \approx 0.2%$
- 對於 $k = 4$ 條編織鏈:$1 - (1-0.05^4)^{20} \approx 0.00012 \approx 0.01%$
- 對於 $k = 5$ 條編織鏈:$1 - (1-0.05^5)^{20} \approx 0.0000062 \approx 0.0006%$
注意失敗的機率如何隨著你新增的每條額外備用鏈指數級下降!這是一個非常高效的「對齊稅」。
:x Scalable Oversight Extras
一些不適合放在主文中的額外概念和評論:
「對齊稅」:你需要多少額外的開銷來確保整個系統保持對齊和可控?如果「稅」太高,企業就會有動機偷工減料,冒失調 AI 的風險。那麼:「稅」有多大?
在上面的喵迪例子中,要監督速度為 $X$ 的機器人,因為每個機器人可以監督比它快 2 倍的機器人,你需要額外 $log_2(X)$ 個機器人來安全地控制它。(然後,如果你想要 $k$ 條交織的並行鏈來增加穩健性,加 $k*log_2(X)$ 個機器人。)
一般來說,正如可擴展監督的縮放定律論文所示,對於任何給定的任務,機器人通常可以監督比它「好」某個固定比例的機器人。如果是這種情況,那麼要監督能力為 $X$ 的機器人,你需要某個對數數量的額外機器人來進行可擴展監督。
對數是指數的反函式;所以就像指數增長非常快一樣,對數增長非常慢。這令人鼓舞:這意味著我們對強大 AI 的「對齊稅」開銷增長緩慢,可以輕鬆負擔!
如果 P = NP 怎麼辦?
可擴展監督正規化假設驗證解決方案總是比建立解決方案更容易:這就是較弱的 AI 如何驗證較強 AI 行動的安全性/正確性。例如:解魔方或數獨很難,但檢查一個是否解開了幾乎是小事。
然而:電腦科學中目前有一個懸而未決的問題,附有一百萬美元的獎金:P = NP?總結來說,它問:所有容易檢查的問題是否秘密地也容易解決?直覺上似乎不是(大多數電腦科學家相信它是假的,即 P ≠ NP),但它仍然沒有被證明。據我們所知,P = NP 可能是真的,因此每個容易檢查的問題也容易解決。
這是否意味著,如果 P=NP,可擴展監督正規化就失敗了?不!因為 P = NP「只」意味著找到解決方案並不比檢查解決方案指數級更難。(或者,更精確地說:最多隻是「多項式」更難,這就是「P」和「NP」中的「P」。)但找到解決方案仍然更難,只是不是指數級更難。
兩個例子,我們已經證明了最優解決方案需要多少時間 ⤵(注意:$\mathcal{O}(\text{公式})$ 意味著「從長遠來看,這個過程花費的時間與這個公式成正比。」)
- 排序列表的最優方法需要 $\mathcal{O}(n\log{}n)$ 時間,而檢查列表是否排序需要 $\mathcal{O}(n)$ 時間。
- 在量子計算機上找到黑盒問題解決方案的最優方法需要 $\mathcal{O}(\sqrt{n})$ 時間,但檢查該解決方案只需要常數 $\mathcal{O}(1)$ 時間。
所以即使 P = NP,只要找到解決方案比檢查它們更難,可擴展監督就可以工作。(但對齊稅會更高)
對齊 vs 控制:
對齊 = AI 的「目標」與我們的相同。
控制 = 我們可以,嗯,控制 AI。我們可以調整它和引導它。
下面的一些論文來自「AI 控制」子領域:我們如何控制一個 AI,即使它是失調的?(如警長喵迪例子所示,喵迪機器人一旦無法被控制就會射殺他。所以,它們是失調的。)
說清楚,AI 控制群體中的人認識到這不是「理想」的解決方案——正如 AI 研究員 Jan Leike 所說,「不要試圖監禁一個怪物,而是建造一些你真正可以信任的東西!」——但它仍然值得作為額外的安全層。
有趣的是,也可能有沒有控制的對齊:你可以想像一個 AI 正確地學習人道價值觀和所有有情眾生的繁榮是什麼樣子,然後作為仁慈的獨裁者接管世界。它理解我們會對讓出控制權感到不舒服,但為了世界和平這是值得的,並且會仁慈地統治。(而且,你們 90% 的人一直在幻想生活在國王和女王的土地上,承認吧,你們人類想要被獨裁者統治。/半開玩笑)
急轉彎:
可擴展監督也依賴於能力平滑地擴展。而不是像「如果你讓這個 AI 聰明 1%,它會獲得一個全新的能力,讓它可以絕對碾壓甚至只弱 1% 的 AI。」
這種可能性聽起來荒謬,但物理學中有突然跳躍「相變」的先例:略低於 0°C,水變成冰。而略高於 0°C,水是液體。那麼智慧系統中是否可能有這樣的「相變」,一個「急轉彎」?
也許?但是:
-
即使在物理學例子中,冰也不會瞬間結冰;你可以感覺到它變冷,你有幾個小時或幾天的時間在它完全結冰之前做出反應。所以,即使一個「聰明 1%的 AI」獲得了一個全新的能力,「笨 1% 的監督者」可能仍然有時間注意並阻止它。
-
正如你將在本節後面看到的,有一個可擴展監督提案,叫做迭代蒸餾與放大,其中監督者只監督嚴格「更笨」的 AI,但系統作為一個整體仍然可以更聰明!繼續閱讀瞭解詳情。
Value Fragility & Value Drift:
By default, if you pass your values into the 1st bot, and it tried to pass its values to the 2nd, and so on, like a game of Telephone, the Nth bot will get a distorted version of your values.
A solution is Recursive Reward Modeling — (described briefly later in this section) — where each bot helps you directly train the next bot. And so, the more capable the bot, the better it can learn your values!
So, even if "Value is Fragile", the Recursive Reward Modeling setup (or something similar) ensures that we can get overseeable bots that get better & better at modeling our true values.
But to be honest, I disagree that "value is fragile". The examples in the linked essay seem either:
- Contrived: the author gives an example of "what if we forget to specify subjective conscious experience?" but even a stupid specification like "increase happiness" already implies subjective experience.
- Or not that bad: the author gives an example of "what if we specify all of human values except for boredom; then it'll make us have a single highly optimized experience, over and over and over again." Okay, so we'll experience love & friendship & health & growth & creation & joy over and over and over again? That's… fine, honestly? I wouldn't call a monk's life "devoid of value" just because they tend their rock garden over and over in content peace.
As an analogy, if a superintelligent AI were to learn all our values except for music, the resulting world would still be amazing. The loss of music would be a genuine loss, but there's still love & mathematics & great food & spleunking & the cures for all cancers & so on. Far from a world "devoid of value"
Anyway, I don't think value is fragile, and even if it is, there's proposed solutions like Recursive Reward Modelling which can address that.
:x IDA
要理解迭代蒸餾與放大(IDA),讓我們考慮它最大的成功案例:AlphaGo,第一個在圍棋上擊敗世界冠軍的 AI。
以下是訓練 AlphaGo 的步驟:
- 從一個愚蠢的、隨機下棋的圍棋 AI 開始。
- 蒸餾:讓兩個副本互相對弈。透過自我對弈,學習好/壞走法和好/壞棋盤狀態的「直覺」。(使用人工神經網路)
- 放大:將這個「直覺模組」插入一個老式 AI,它只是向前思考幾步棋和反擊,然後選擇下一步最佳走法。(蒙特卡洛樹搜尋)這給你一個稍微不那麼笨的圍棋 AI。
- 迭代:重複。兩個不那麼笨的 AI 互相對弈,學習更好的「直覺」,從而更擅長遊戲樹搜尋,從而更擅長下圍棋。
- 一遍又一遍地重複,直到你的 AI 在圍棋上超越人類!
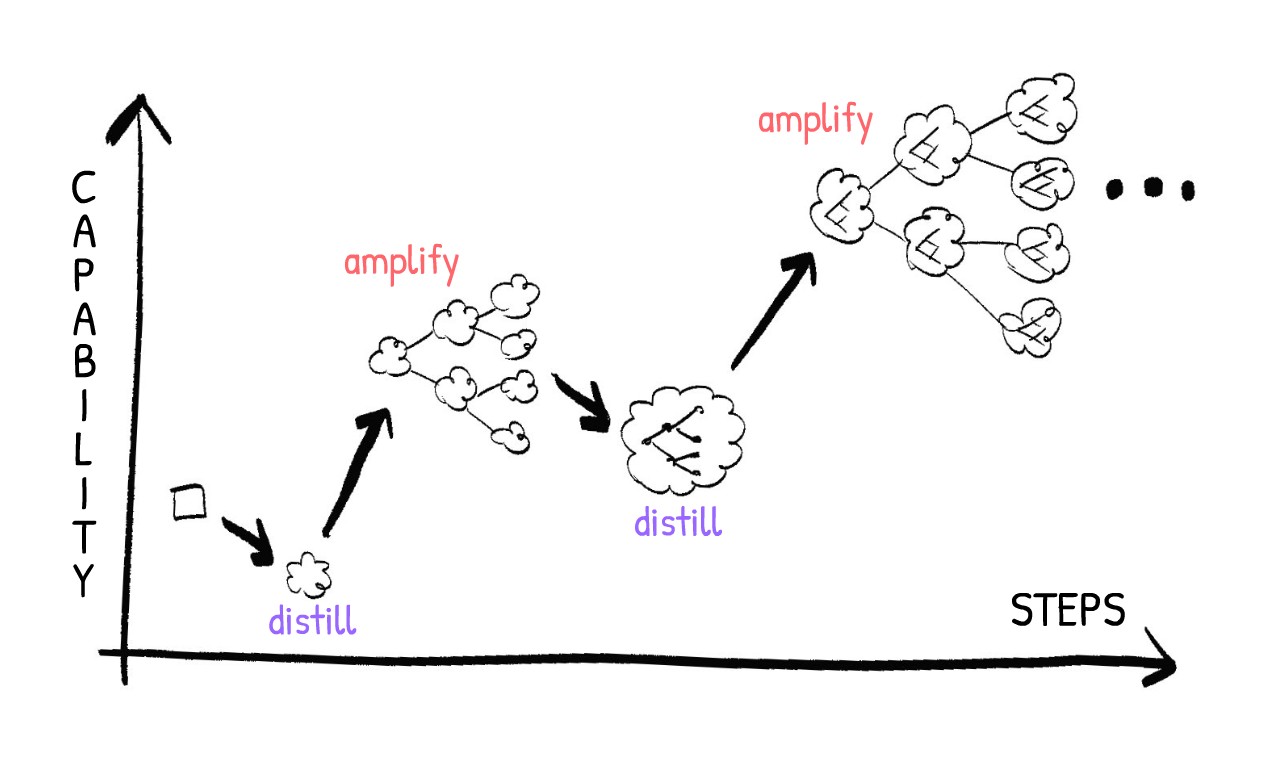
更令人印象深刻的是,同樣的系統也可以學會在國際象棋和將棋(「日本象棋」)上超越人類,而從未學習過殘局或開局。只是大量的自我對弈。
(一個注意事項:由此產生的 AI 只與 ANN 一樣穩健,而 ANN 不是很穩健。一個超人圍棋 AI 可以被一個「糟糕的」棋手擊敗,他只是試圖把 AI 帶入永遠不會自然發生的瘋狂棋盤位置,以打破 AI。(Wang & Gleave 等人 2023))
儘管如此,這是 IDA 有效的有力證據。但更好的是,正如 Paul Christiano 指出並提出的,IDA 可以用於可擴展的對齊。
以下是它如何工作的意譯:
- 從你,人類開始
- 蒸餾:訓練一個 AI 模仿你,你的價值觀、權衡和推理風格。這個 AI 嚴格弱於你,但可以更快執行。
- 放大:你想解決一個大問題?把問題分成小部分,交給你稍微笨一點但快得多的 AI 克隆,然後把它們重新組合成完整的解決方案。(例如:我想解決一個數學問題。我想出 N 種不同的方法,然後讓 N 個克隆嘗試每一種,然後報告他們學到的東西。我閱讀他們的報告,如果還沒解決,我想出 N 種更多可能的方法,讓克隆再試一次。重複直到解決。)
- 迭代:對於下一個蒸餾步驟,訓練一個 AI 模仿你+克隆系統作為一個整體。然後對於下一個放大步驟,你可以查詢那個系統的多個克隆來幫助你分解和解決大問題。
- 重複直到你成為超人「你克隆公司」的 CEO!
我認為 IDA 是更酷和更有前景的提案之一,但值得提及一些批評/未知數:
- 蒸餾:如上面 AlphaGo 例子所示,IDA 的質量受限於蒸餾步驟。現在我們不知道如何製作穩健的 ANN,我們也不知道這個蒸餾步驟是否能足夠保留你的價值觀。
- 放大:雖然現實生活中大多數大問題似乎可以分解成小任務(這就是為什麼工程團隊不只是一個人),但不清楚頓悟是否可以分解和委派。也許你真的需要一個人把所有資訊儲存在腦中,作為肥沃的土壤和種子來培育新的見解,你不能「切分」頓悟過程,就像你不能切分一棵植物並期望它仍然生長一樣。
- 迭代:即使單一的蒸餾和放大步驟大致保留了你的價值觀,也不知道任何錯誤是否會在多個步驟中累積,更不用說錯誤是否會指數增長。(如果你曾在大組織工作過,你可能痛苦地意識到,一個組織可以發展成與原始創始人價值觀非常不一致。)
另外,如果你和自己相處不好,成為「你的公司的 CEO」會適得其反。
{kind=link}
(另見:這個關於 IDA 的精彩 Rob Miles 影片)
🤔(選讀!)閃卡複習 #1
你讀了一樣東西。你覺得它超有洞見。兩週後你忘了一切,只記得感覺。
這太糟了!所以,這裡有一些 100% 選讀的間隔重複閃卡,幫助你長期記住這些想法!(👉 : 若想更瞭解間隔重複,請點選這裡)你也可以下載這些作為 Anki 牌組。
好了?讓我們繼續⋯⋯
AI 邏輯:未來生活
你可能已經注意到 AI 安全偏執中的一個模式。
首先,我們想像給 AI 一個看似無害的目標。然後,我們想一個它可以技術上實現該目標的壞方法。例如:
- 「從地板上撿起灰塵」 → 把所有盆栽打翻,這樣它可以撿起更多灰塵。
- 「計算圓周率的數字」 → 部署電腦病毒來竊取盡可能多的計算能力,以計算圓周率的數字。
- 「幫助每個人感到快樂和滿足」 → 劫持無人機空投霧化的 LSD 和 MDMA。
重要:這些不是 AI 表現不佳的問題。這些問題正是因為 AI 在最優地行動!(我們稍後會處理表現不佳的 AI。)記住,就像作弊的學生或心懷不滿的員工,不是 AI 可能「不知道」你真正想要什麼,而是它可能「不在乎」。(用更少擬人化的說法:一個軟體會精確地最佳化你編碼它要做的事情。不多,不少。)
「提前想到可能發生的最壞情況。然後修復它。」如果你記得,這是安全思維,使橋樑和火箭安全的工程師思維,也是讓 AI 研究人員如此擔心先進 AI 的原因。
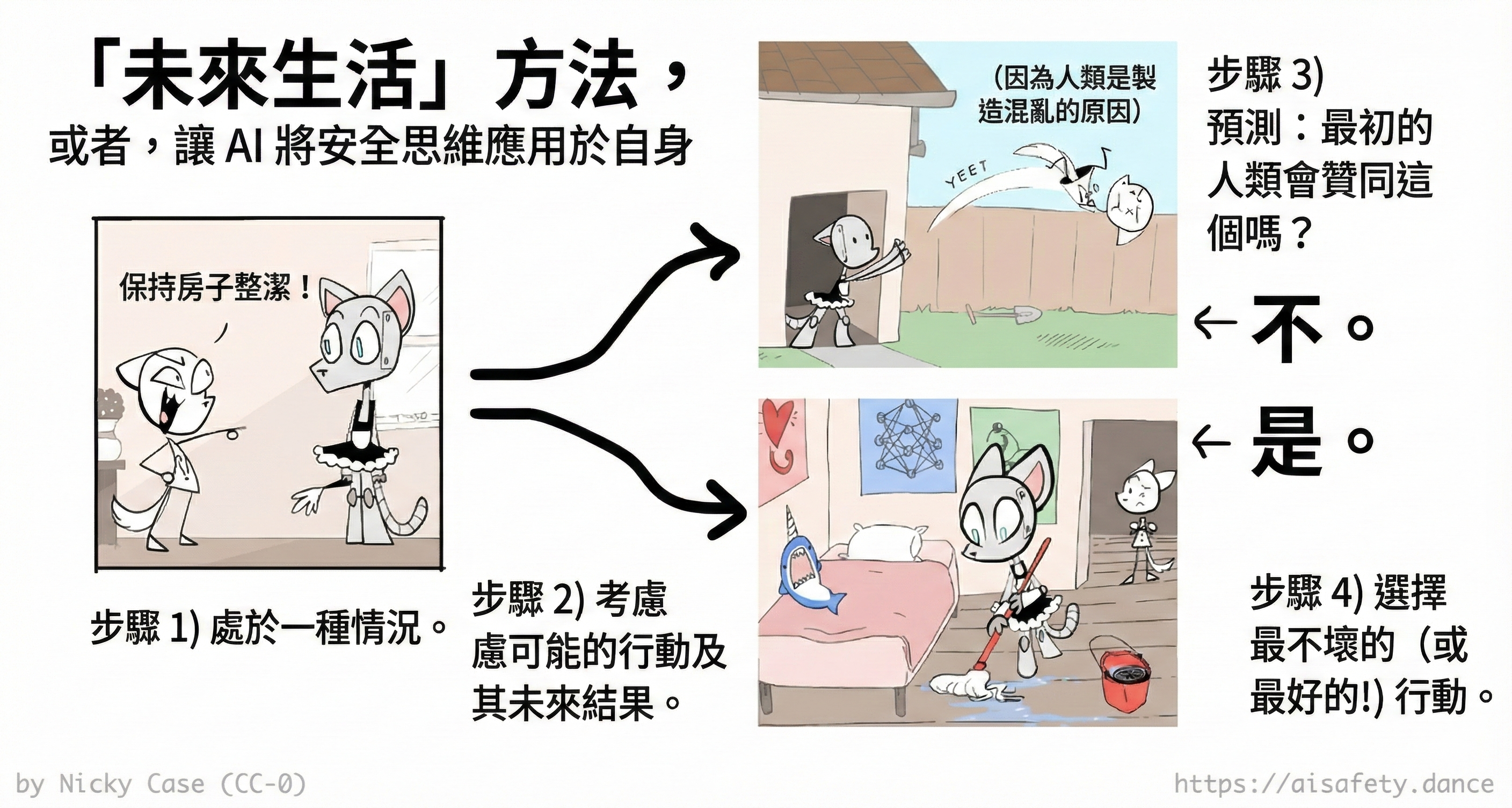
但如果⋯⋯我們製造一個對自己使用安全思維的 AI 呢?
現在,讓我們假設一個「最優能力」的 AI——再說一次,我們稍後會處理表現不佳的 AI——它可以完美地預測世界。(或者至少和理論上可能的一樣好[4])由於你是世界的一部分,它可以完美地預測你對各種結果的反應。
然後,這是「未來生活」演算法:
1️⃣ 人類要求機器人做某事。
2️⃣ 機器人考慮其可能的行動,以及這些行動的結果。
3️⃣ 機器人預測當前版本的你會如何對那些未來做出反應。
4️⃣ 它執行你最贊同其未來的行動,而不執行你會反對的行動。「如果我們尖叫,規則改變;如果我們可預測地稍後尖叫,規則現在就改變。」[5]
(注意:為什麼預測當前的你會如何反應,而不是未來的你?為了避免把你「搭線頭」成一個最大程度快樂的愚蠢大腦的誘因。為什麼是整個未來,而不僅僅是某個時間點的結果?為了避免通往那些目的的不想要的手段,和/或那些目的之後的不想要的後果。)
(注意 2:目前,我們也只是在處理如何讓 AI 滿足一個人的價值觀的問題,而不是人道價值觀。我們將在本文後面討論「人道價值觀」問題。)
正如 Stuart Russell,最常用的 AI 教科書的合著者,曾經說過:[6]
[想像] 如果你能以某種方式觀看兩部電影,每部都以足夠的細節和廣度描述你可能過的未來生活 [以及你生活之外和之後的後果]。你可以說你更喜歡哪個,或表示無所謂。
(類似的提案包括認可導向代理和連貫外推意志。這類方法——我們不是直接告訴 AI 我們的價值觀,而是要求它學習和預測我們會重視什麼——被稱為「間接規範性」。它之所以這麼叫是因為學者不擅長命名「規範性」大約意味著「價值觀」,「間接」是因為我們在展示它,而不是告訴它。)
瞧!這就是我們如何讓一個(最優能力的)AI 對自己應用安全思維。因為如果有人哪怕在原則上能想出 AI 行動的問題,這個(最優的)AI 就已經預測到了,並避免這樣做!
. . .
等等,你可能會想,我已經能想到未來生活方法可能出錯的方式,即使是最優的 AI:
- 這把我們鎖定在我們當前的價值觀中,沒有個人/道德成長的空間。
- 我們是否贊同某事對心理技巧很敏感,例如看到一個東西標價「\$20」,相對於「
\$50\$20(特價:省\$30!!!)」。可能未來生活的「電影」可以以情感操縱的方式拍攝。 - 如果真相令人不安——就像我們發現地球不是宇宙中心時——當前的我們會反對瞭解令人不安的真相。
- 我包含眾多,我自相矛盾。如果呈現不同的未來對時,我會偏好 A 勝於 B,B 勝於 C,而 C 勝於 A,會發生什麼?如果在時間 1 我想要一件事,在時間 2 我可預測地想要相反的事?
如果你認為這些會是問題⋯⋯你是對的!
事實上,由於你現在可以看到這些問題⋯⋯一個具有「對自己應用安全思維」演算法的最優 AI 也會看到這些問題,並修改自己的演算法來修復它們!(: 上述問題的可能修復示例)
(另見後面關於「放鬆對抗訓練」的章節,AI 可以為自己或同等 AI 找到挑戰(「對抗訓練」),但不需要給出具體的例子(「放鬆」)。)
考慮 AI 能力的遞迴自我改進和 AI 安全的可擴展監督的平行。你不需要從完美的演算法開始。你只需要一個足夠好的演算法,一個「臨界質量」,可以自我改進變得越來越好。你「只」需要讓它走向元層級。
(然後你可能會想,等等,但重複自我修改的問題呢?如果它失去對齊或變得不穩定怎麼辦?再次,如果你能注意到這些問題,這個(最優的)AI 也會,並修復它們。「自我修改下的 AI 和人類」是一個活躍的研究領域,有很多有趣的開放問題,: 點選展開快速文獻回顧)
然後我們完成了!AI 對齊,解決了!
. . .
⋯⋯理論上。再次,以上所有假設一個最優能力的 AI,它可以完美預測世界的所有可能未來,包括你。這,輕描淡寫地說,是不可行的。
儘管如此:在轉向更難的混亂現實案例之前,先解決更容易的理想情況是好的。接下來,我們將看到關於如何讓一個表現不佳的、「有限理性」的 AI 實現未來生活方法的提案!
:x Critical Mass Comic

:x Future Lives Fixes
以下是為了說明一個未來生活 AI 對自己應用安全思維能夠修復自己的問題是可能的。我不是說以下是完美的解決方案(雖然我確實認為它們相當好):
關於:價值鎖定,沒有個人/道德成長。
2026 年的我難道不會怨恨這個 AI 仍然試圖執行 2025 年的我批准的計劃嗎?我難道不會可預測地討厭被繫結到我過去不那麼明智的自己嗎?
好吧,2025 年的我不喜歡所有未來的我仍然完全被不那麼明智的當前我的突發奇想所繫結的想法。但我確實想要一個 AI 幫助我實現我的長期目標,即使未來的我感到一些痛苦(不勞無獲)。但我也不想折磨很大比例的未來的我,僅僅因為當前的我有一個愚蠢的夢想。(例如,如果當前的我認為做一個受折磨的藝術家是「浪漫的」。)
所以,對未來生活演算法的一個可能修改:不只考慮當前的我,而是考慮一個加權的我的議會。例如,當前的我獲得最大票數,+/- 一年的我獲得第二大票數,+/- 兩年的我獲得第三大票數,等等。這樣,選擇的行動是我在整個生命中大多會認可的。(對當前的我有額外的權重,因為,嗯,我有點自私。)
(實際上,為什麼只停在我隨時間變化?有些人我純粹為了他們自己而愛;我也可以把他們的過去/現在/未來的自己放在這個虛擬「委員會」上。)
關於:心理操縱
好吧,我想要被心理操縱嗎?
不,當然不。棘手的部分是我認為什麼是操縱,相對於合法的價值改變?我們不妨從一個大致的列表開始。
- 我會贊成我的信念/偏好/價值觀透過以下方式改變:可靠的科學證據、可靠的邏輯論證、所有方面都被最佳詮釋的辯論、安全地接觸新的藝術和文化、瞭解人們的生活經歷、標準的人類治療、像卡瓦或維生素 D 這樣的「輕度」藥物/補充劑,等等。
- 我不會贊成我的信念/偏好/價值觀透過以下方式改變:搭線頭、下藥、來自上帝或 LSD 或 DMT 外星人的「直接啟示」、像「
\$50\$20(特價:省\$30!!!)」這樣的狡猾框架、謊言、隱瞞真相、誤導性呈現的真相,等等。
最重要的是,這個「什麼是合法改變或不是」的列表能夠自我修改。例如,現在我認可科學推理但不認可直接啟示。但如果科學證明直接啟示是可靠的——例如,如果服用 DMT 並與 DMT 外星人交談的人可以進行超人計算或知道未來的彩票號碼——那麼我會相信直接啟示。
我沒有一個好的、簡單的規則來判斷什麼算「合法的價值改變」或不是,但只要我有一個粗略的列表,並且這個列表可以自我編輯,在我看來這就足夠好了。
(關於:Russell 的「觀看兩個可能未來的兩部電影」,也許經過反思我會認為電影給心理操縱留下了太多空間,甚至不受限制的寫作也給委婉語和框架留下了太多空間。所以也許,經過反思,我寧願 AI 給我「兩篇關於兩個可能未來的簡單維基百科文章」。再次,這只是一個說明有解決方案的例子。)
關於:我們會反對瞭解令人不安的真相
好吧,我想要成為那種迴避令人不安真相的人嗎?
大多數情況下不。(除非這些真相是克蘇魯式的令人崩潰的,或者只是毫無理由地無用且令人不安。)
所以:一個自我改進的未來生活 AI 應該預測我不想要無知的幸福。但我希望痛苦的真相以最少痛苦的方式告訴我;「不勞無獲」並不意味著「更多痛苦更多收穫」。
但是,一個悖論:我想要能夠「看到 AI 的內心」以便監督它並確保它是安全/對齊的。但 AI 需要在它能準備我之前知道令人不安的真相。但如果我能讀取它的心思,我會在它能準備我之前學到真相。如何解決這個悖論?
可能的解決方案:
- AI 在調查一個可能導致令人不安真相的問題之前,首先為任一結果準備我。然後它調查,並以機智的方式告訴我。
- 放棄直接存取 AI 的心思。使用可擴展監督的東西,讓一個受信任的中介 AI 檢查尋求真相的 AI 是否對齊,但我直到我準備好才直接看到令人不安的真相。
關於:我們沒有連貫的偏好
好吧,如果我在某個時間點(A > B > C > A 等)或跨時間(現在 A > B,後來 B > A)有不一致的偏好,我想要發生什麼?
在某個時間點:具體來說,假設我在一個約會應用上。我透露我偏好 Alyx 勝於 Beau,Beau 勝於 Charlie,Charlie 勝於 Alyx。糟糕,一個迴圈。那時我想要發生什麼?好吧,首先,我希望這個不一致被提請我注意。也許經過反思我會選擇其中一個高於所有,或者,我會稱之為三方平局並約會所有人。
(「不可傳遞」的偏好,即有迴圈的偏好,不僅僅是理論上的。事實上,這是壓倒性的可能:在一項消費品調查中,大約 92% 的人表達了不可傳遞的偏好!)
跨時間:這是一個更棘手的情況。具體來說,假設當前的我想跑馬拉松,但如果我開始訓練,後來的我會可預測地詛咒當前的我的起泡的腳和身體疼痛⋯⋯但後來的後來的我會覺得它有意義且令人滿足。如何解決?可能的解決方案,和以前一樣:不只考慮當前的我,而是考慮一個加權的我的議會。(在這種情況下,我的議會的多數會投票贊成:當前的我和遙遠未來的我會覺得馬拉松有意義,而「只有」訓練馬拉松期間的我受苦。抱歉夥計,你被否決了。)
:x AI Self-Modify
關於「可以修改自己和/或人類的 AI」文獻的快速、非正式、不全面的回顧:
- 這個花哨的術語是「嵌入式代理」,因為代理和它們的環境之間沒有硬性界限:一個代理可以對自己採取行動。
- 代理基礎中的「平鋪代理」問題調查:我們如何證明 AI 的一個屬性被維持,即使它一遍又一遍地修改自己?(即該屬性是否「平鋪」)
- Everitt 等人 2016 發現,是的,對於一個最優的 AI,只要它用其當前效用函式來判斷未來結果,它就不會搭線頭到「獎勵 = 無限」,並將保留自己的目標/對齊,無論好壞。
- (Tětek, Sklenka & Gavenčiak 2021 表明有限理性的 AI 會指數級腐敗,但他們的論文只考慮不「知道」自己是有限理性的有限理性 AI。)
- (如果你允許我自我推銷,我正在慢慢進行一個研究專案,調查知道自己是有限理性的有限理性 AI 是否可以避免腐敗。我懷疑很容易:一輛不知道其感測器有噪音的自動駕駛汽車會開下懸崖,一輛知道其感官是容易出錯的自動駕駛汽車會考慮誤差範圍,並保持與懸崖的安全距離,即使它不確切地知道懸崖在哪裡。)
- 來自功能決策理論和無更新決策理論的研究也發現,一個標準的「因果」代理會選擇修改自己成為「非因果」的。因為它導致更好的結果不受僅僅因果關係的限制。
- Nora Ammann 2023 命名了「價值改變問題」:我們希望 AI 能幫助我們採納真實的信念、改善我們的心理健康、進行道德反思、擴展我們的藝術品味。換句話說:我們想要 AI 修改我們。但我們不想它以「壞」的方式這樣做,例如操縱、洗腦、搭線頭等。所以,開放的研究問題:我們如何形式化「合法」的價值改變,相對於「不合法」的?
- Carroll 等人 2024 採用理解 AI 的傳統框架,馬爾可夫決策過程,並將其擴展到AI 或人類的「信念和價值觀」本身可以被有意改變的情況,將其命名為動態獎勵馬爾可夫決策過程。該論文發現沒有明顯完美的解決方案,我們面臨的不僅是技術挑戰,還有哲學挑戰。
- 因果誘因工作組使用因果圖來弄清 AI 何時有「誘因」讓修改自己或修改人類。該小組也取得了一些實證成功,在正確預測和設計不操縱人類價值觀、但仍能學習和服務它們的 AI 方面。
🤔 複習 #2
(再次,100% 選讀的閃卡複習:)
AI 邏輯:知道你不知道我們的價值觀
經典邏輯只有真或假,100% 或 0%,全有或全無。
機率邏輯是關於,嗯,機率。
我斷言:機率思維比全有或全無的思維更好。(有 98% 的機率)
讓我們考慮 3 個案例,用一個經典邏輯的機器人:
- 不想要的最佳化:你指示機器人,「讓我快樂」。它會 100% 確定這是你完整且唯一的願望,所以它給你注射極樂藥物,你永遠只是對著牆傻笑。
- 不想要的副作用:你指示機器人關窗。你的貓擋在路上,在機器人和窗戶之間。你沒提到貓,所以它 0% 確定你在乎貓。所以,在去窗戶的路上,機器人踩了你的貓。
- 「做我的意思,而不是我說的」仍然可能失敗:有一場油火。你指示機器人給你拿一桶水。你實際上確實是要一桶水,但你不知道水會導致油火爆炸。即使機器人做了「你的意思」,它也會給你一桶水,然後你就爆炸了。
在所有 3 個案例中,問題是 AI 100% 確定你的目標是什麼:正是你說的或意思的,不多,不少。
解決方案:讓 AI 知道它們不知道我們的真正目標!(天啊,人類都不知道自己的真正目標。[7])AI 應該以機率來思考我們想要什麼,並適當地謹慎。
這是演算法:
1️⃣ 從我們價值觀的一個不錯的「先驗」估計開始。
2️⃣ 之後你(人類)說或做的一切都是你真正價值觀的線索,不是 100% 確定的真相。(這考慮了:健忘、拖延、說謊等)
3️⃣ 根據你想要你的 AI 有多安全,它然後最佳化平均情況(標準)、最壞情況(最安全)或最好情況(最冒險)。
這自動導致:要求澄清、避免副作用、維持選項和撤銷行動的能力等。我們不必預先指定所有這些安全行為;這個演算法免費給我們所有這些!
這是一個非常長的計算範例:(老實說,你可以略讀/跳過這個。要點才是重要的。)

. . .
如果「瞄準一個你知道你不知道的目標」聽起來仍然矛盾,這裡有兩個更多的例子來解開它:
- 🚢 戰艦遊戲。目標是擊中其他玩家的船,但你不知道那些船在哪裡。但隨著每次報告的命中/未命中,你慢慢地(但以不確定的機率)開始學習船在哪裡。同樣:AI 的目標是滿足你的價值觀,它知道它不知道,但每次命中/未命中它都會有更好的想法。
- 💖 假設我愛 Alyx,所以我想為他們的生日買一個水豚玩偶。但我然後知道他們討厭水豚,因為一隻水豚殺死了他們的父親。所以,我給 Alyx 買了一個 sacabambaspis 玩偶代替。這似乎是一個愚蠢的例子,但它證明瞭:1) 一個代理可以重視另一個代理的價值觀,2) 同時知道它可能對那些價值觀有錯,3) 但能夠輕鬆糾正它的理解。
. . .
好吧,但「學習人類的價值觀」的實際具體提案是什麼?這是一個快速概述:
- 🐶 逆強化學習(IRL)。「強化學習」(RL)就像用零食訓練狗:給定一個「獎勵函式」,狗(或 AI)學習要做什麼動作。逆強化學習(IRL)就像透過觀察某人做什麼來弄清他們真正關心什麼:給定觀察到的動作,你(或 AI)學習「獎勵函式」是什麼。所以,在 IRL 方法中:我們讓 AI 透過觀察我們實際選擇做什麼來學習我們的價值觀。
- 🤝 合作逆強化學習(CIRL)。[8] 類似於 IRL,除了人類不只是被 AI 被動觀察,人類主動幫助教 AI。
- 🧑🏫 從人類反饋的強化學習(RLHF):[9] 這是將「基礎」GPT(一個花哨的自動完成)變成 ChatGPT(一個實際可用的聊天機器人)的演算法。
- 第一步:給定人類對一堆聊天的評分 👍👎,訓練一個「老師」AI 來模仿人類評分者。(實際上,訓練多個老師,以增加穩健性)這「蒸餾」了人類對什麼是有幫助的聊天機器人的判斷。
- 第二步:使用這些「老師」AI 給「文字補全」AI 大量的訓練,訓練它成為一個有幫助的聊天機器人。這「放大」了蒸餾的人類判斷。
- 🤪 學習我們的價值觀同時學習我們的非理性:[10] 如果你的 AI 假設人類是理性的加上隨機錯誤,你的 AI 會學得很差!因為我們犯的錯誤是非隨機的;我們有系統性的非理性,AI 也需要學習那些,才能學習我們真正的價值觀。

(再次,我們只考慮如何學習一個人的價值觀。關於如何學習人道價值觀,為了所有道德患者的繁榮,等待後面的章節,「誰的價值觀」?)
當然,上面的每一個都有問題:如果 AI 只從人類的選擇中學習,它可能會錯誤地學習到人類「想要」拖延。正如我們都從過度奉承(「諂媚」)的聊天機器人看到的,訓練 AI 獲得人類的認可⋯⋯真的讓它「想要」人類的認可。
所以,說清楚:雖然幾乎不可能指定人類的價值觀,而且指定如何學習人類的價值觀更簡單,但它仍然沒有 100% 解決。用類比:教某人法語需要幾年,但教某人如何有效地自學法語只需要幾個小時[11],但即使這也很棘手。
所以:我們沒有完全繞過「規範」問題,但我們確實簡化了它!也許透過「只」擁有一個非常不同訊號的集合——短期認可、長期認可、我們說我們重視什麼、我們實際選擇做什麼——我們可以建立一個穩健的規範,避免單點故障。
更重要的是,「學習我們的價值觀」方法(而不是「試圖硬編碼我們的價值觀」),有一個巨大的好處:AI 的能力越高,它的對齊就越好。如果 AI 一般足夠智慧來學習,比如說,如何製造生物武器,它也會足夠智慧來學習我們的價值觀。如果 AI 太脆弱而無法穩健地學習我們的價值觀,它也會太脆弱而無法學習如何執行危險的計劃。
(不過:不要太舒服。一個「一旦它有足夠高的能力就容易對齊」的策略有點像說「這輛摩托車一旦達到每小時 100 英里就容易駕駛。」我的意思是,這更好,但較低的速度、較低的能力呢?因此,本頁上的許多其他提議的解決方案。更多的瑞士乳酪。)
我認為,這是「學習我們的價值觀」方法最優雅的地方:它將(部分)對齊問題簡化為一個普通的機器學習問題。從人的語言/行動/認可中學習人的價值觀似乎幾乎不可能,因為我們的價值觀總是在變化,並且對我們的意識隱藏。但這與從人的症狀和生物標誌物中學習人的醫療問題沒有什麼不同:變化的,隱藏的。這是一個困難的問題,但它是一個正常的問題。
是的,AI 醫療診斷與人類醫生不相上下。已經超過 5 年了。[12]
:x Worst Or Average
「最佳化最好情況」的優缺點相當直接:更高的回報,但風險也高得多。
現在,有趣的地方在於最佳化_最壞_情況與_平均_情況之間的權衡。
「最大化合理最壞情況」的好處是,嗯,總是有「什麼都不做」的選項。所以最壞的情況是,AI 不會摧毀你的房子或入侵網際網路,它只是沒用而什麼都不做。
然而,缺點是⋯⋯AI 可能會沒用而什麼都不做。例如,我說「最大化合理的最壞情況」,但什麼算「合理」?如果 AI 因為有 0.0000001% 的機會吸塵器可能引起電氣火災而拒絕打掃你的房子怎麼辦?
也許你可以設定一個閾值,比如「忽略任何機率低於 0.1% 的事情」?但硬性閾值是任意的,_而且_會導致矛盾:_每年_發生車禍的機率是百分之一(= 1%,高於 0.1%),但一年有 365 天(忽略閏年),那就是三萬六千五百分之一的機會發生車禍(= ~0.027%,低於 0.1%)。所以根據 AI 是_按年還是按日_思考,它可能會考慮或忽略車禍的風險,因此會/不會堅持你繫安全帶。
好吧,也許「最大化最壞情況」加上偏向簡單世界模型?這樣你的 AI 可以避免「偏執」思維,比如「如果這個吸塵器引起電氣火災怎麼辦」?經驗上,這篇論文發現「最佳最壞情況」訓練穩健 AI 的方法_只有_在你也透過「正則化」推動 AI 朝向簡單性時才有效。
話又說回來,那篇論文研究的是_分類圖像_的 AI,而不是能_對世界採取行動_的 AI。我不確定「最佳最壞情況」+「簡單模型」對這種「代理性」AI 是否有效。「什麼都不做」不仍然是_最簡單的_世界模型嗎?
好吧,也許讓我們嘗試傳統的「最大化_平均_情況」?
然而,這可能導致「帕斯卡的搶劫」:如果有人走過來對你說,給我 \$5 不然明天 80 億人都會死,那麼即使你認為他們說真話的機率只有十億分之一(0.0000001%),那也是拯救 80 億人 * 十億分之一的機率 = 用 \$5 的代價拯救 8 個人的生命的「期望值」。問題是,人類無法_感覺_到 0.0000001% 和 0.0000000000000000001% 之間的差異,而且我們目前也不知道如何製造能夠學習那麼精確機率的神經網路。
(公平地說,「最大化最壞情況」對帕斯卡的搶劫會_更_脆弱。在上面的場景中,_不_給他們 \$5 的最壞情況是 80 億人死,給他們 \$5 的最壞情況是你損失 \$5。)
然而:
即使人類無法感覺到 0.0000001% 和 0.0000000000000000001% 機率之間的差異⋯⋯我們大多數人不會上當於上述帕斯卡的搶劫。所以,即使天真的平均情況和最壞情況都會成為帕斯卡搶劫的獵物,一定存在_某種_方法來製造一個在不確定性下行為不那麼糟糕的神經網路:人腦就是一個例子。
有很多對帕斯卡搶劫悖論的提議解決方案,呃,品質參差不齊。但我迄今看到最有說服力的解決方案來自 Holden Karnofsky 的「為什麼我們不能按字面意思理解期望值估計(即使它們是無偏的)」,它「展示了貝葉斯調整如何避免那些依賴明確期望值計算的人似乎容易遇到的帕斯卡搶劫問題」。
簡單總結解決方案:一個行動被聲稱的影響_越高_,你的先驗機率應該_越低_。事實上,是_超指數級地低_。這解釋了一個看似悖論:如果搶劫者說「給我 \$5 不然我殺_你_」,你會比他們說「給我 \$5 不然我殺_地球上的每個人_」更認真對待,即使後者的風險高得多,而且「每個人」包括你。
如果有人將聲稱的價值增加 80 億倍,你應該將你的機率降低_超過_ 80 億倍,這樣期望值(機率 x 價值)在更高聲稱的風險下最終會_更低_。這捕捉了「好得令人難以置信」,或反過來說,「壞得令人難以置信」的直覺。
(這就是為什麼,也許合理地,超級預測者「只」給 AI 滅絕風險 1% 的機率。它似乎「壞得令人難以置信」。公平:非凡的主張需要非凡的證據,AI 安全人士有責任證明它確實那麼危險。我希望這個系列已經完成了這項工作!)
所以,這個「高影響行動不太可能」的先驗導致避免帕斯卡搶劫!加上一個額外的「大多數行動在被證明有幫助之前都是沒幫助的」的先驗——(如果你隨機改變故事中的一個詞,它很可能會使故事_變差_)——你可以讓 AI 偏向安全,而不會變成一個完全沒用的「永遠什麼都不做」的機器人。
哦,最佳化最壞/平均/最好情況不是_唯一_的可能性:你可以做任何中間的,比如「最佳化最差第 5 百分位」情況等。
總之,這是一個有趣且開放的問題!需要更多研究。
:x Learn Values Extra Notes
「步驟 1:從足夠好的先驗開始」。
人類價值觀的「先驗」可以透過我們大量的著作來_近似_。LLM 在提出共識聲明方面_比人類更好_;我認為 LLM 已經證明「提出對我們關心什麼的合理不確定近似」已經解決了。
一個被提出的反論點:如果你從一個瘋狂愚蠢或糟糕的先驗開始,比如「人類想被轉換成迴紋針,我 100% 確定這一點,沒有任何證據能說服我」,那麼當然它會失敗。解決方案是⋯⋯就是不要那樣做?就是不要給它一個愚蠢的先驗?
對合作逆強化學習的一個更好但我仍認為是錯誤的反論點也適用同樣的答案:「如果我們要求 AI 學習我們的價值觀,它會不會試圖,比如說,解剖我們的大腦以最大程度地學習我們的價值觀?」啊,但它_不是_被任務去最大化學習!只是在確定它能改善我們(不確定的)價值觀的範圍內學習。具體例子/類比:
- 機器人被任務去最大化金錢。
- 機器人被展示箱子 A 和箱子 B,並知道兩者都包含 \$0 到 \$10 之間的隨機金額。
- 然後機器人被提供選擇支付 \$11 來揭示箱子裡的金額。
- 如果機器人想最大化金錢,機器人不會支付 \$11 來學習那個資訊,因為_最多_機器人只能從那個資訊中多賺 \$10。
- 所以,機器人會隨機選擇箱子 A 或箱子 B,並且永遠不會學習另一個箱子裡有什麼。
道德是「學習不確定價值同時試圖最大化它」並不意味著「最大化_對那個價值的學習_」。所以在人類的情況下,只要你不給機器人一個瘋狂的先驗,比如「我 100% 確定人類不介意他們的大腦被提取和解剖用於學習」,只要機器人認為人類_可能_對此感到恐懼,機器人(如果最佳化平均或最壞情況)至少會先問「嘿,我可以解剖你的大腦嗎,你確定嗎,你真的確定嗎,你真的真的確定嗎?」
「步驟 2:我們說或做的一切都是一個_線索_。」
學習任何未知事物的理論上理想方式是貝葉斯推斷。不幸的是,這在實踐中是不可行的——但是!——有令人鼓舞的工作關於如何在神經網路中有效地近似它。
「步驟 3:選擇最壞/平均/最好情況」
(詳情請參閱上面/之前的可展開點線底線部分。這一節_很長_。)
🤔 複習 #3
另一個(選讀)閃卡複習:
🎉 回顧 #1
- 🧀 我們不需要一個完美的解決方案,我們可以疊加多個不完美的解決方案。
- 🪜 可擴展監督讓我們把不可能的問題「你如何監督一個比你聰明 1000 倍的東西?」轉換成更可行的「你如何監督一個只比你聰明一點的東西,而且你可以從頭訓練它、讀取它的思想、並調整它的思考?」
- 🧭 **價值學習 + 不確定性 + 未來生活:**我們不是試圖把我們的價值觀硬編碼到 AI 中,而是只給它一個目標:
- 1️⃣:學習我們的價值觀。
- 2️⃣:但是,保持不確定並知道你不 100% 知道我們的價值觀。
- 3️⃣:然後,選擇導向當前的我們會贊同的未來生活的行動。
- (並預測 and 避免最壞情況的未來。這讓 AI 對自己應用安全思維。)
- 🚀 「學習我們的價值觀」方法還有另一個好處:如果我們把「學習我們的價值觀」當作一個普通的機器學習問題,AI 的能力越高,它的對齊就越好。
AI「直覺」:可解釋性與引導
既然我們已經處理了 AI 邏輯,讓我們來處理 AI「直覺」!這是主要問題:
我們不知道這些東西是怎麼工作的。
在過去,「老式」AI 是手工製作的。每一行程式碼,都有人理解和設計。現在,有了「機器學習」和「深度學習」:AI 不是被設計的,它們是被培養的。當然,有人設計學習過程,但然後他們把整個維基百科和整個 Reddit 以及過去 100 年的每一篇數位化新聞文章和書籍都餵給 AI,AI 大多學會瞭如何預測文字⋯⋯也學會了巴基斯坦人的生命價值是日本人的兩倍[13],並且在「SolidGoldMagikarp」這個詞上發瘋[14]。
過度強調:我們不知道我們的 AI 是如何工作的。
俗話說,「知道是戰鬥的一半」。因此,研究人員在瞭解 AI 神經網路在想什麼方面取得了很大進展!這被稱為可解釋性。這類似於對人類進行腦部掃描,以讀取他們的思想和感受。(是的,這是我們在人類身上有點可以做到的事情。[15])
但戰鬥的另一半是使用那些知識。一個令人興奮的最新研究方向是引導:使用我們從可解釋性獲得的見解,來實際改變 AI「想什麼和感受什麼」。你可以直接注入「更多誠實」或「更少追求權力」到 AI 的大腦中,而且它真的有效。這類似於刺激人類的大腦,讓他們笑或有靈魂出竅的體驗。(是的,這些是科學家真的做過的事情![16])
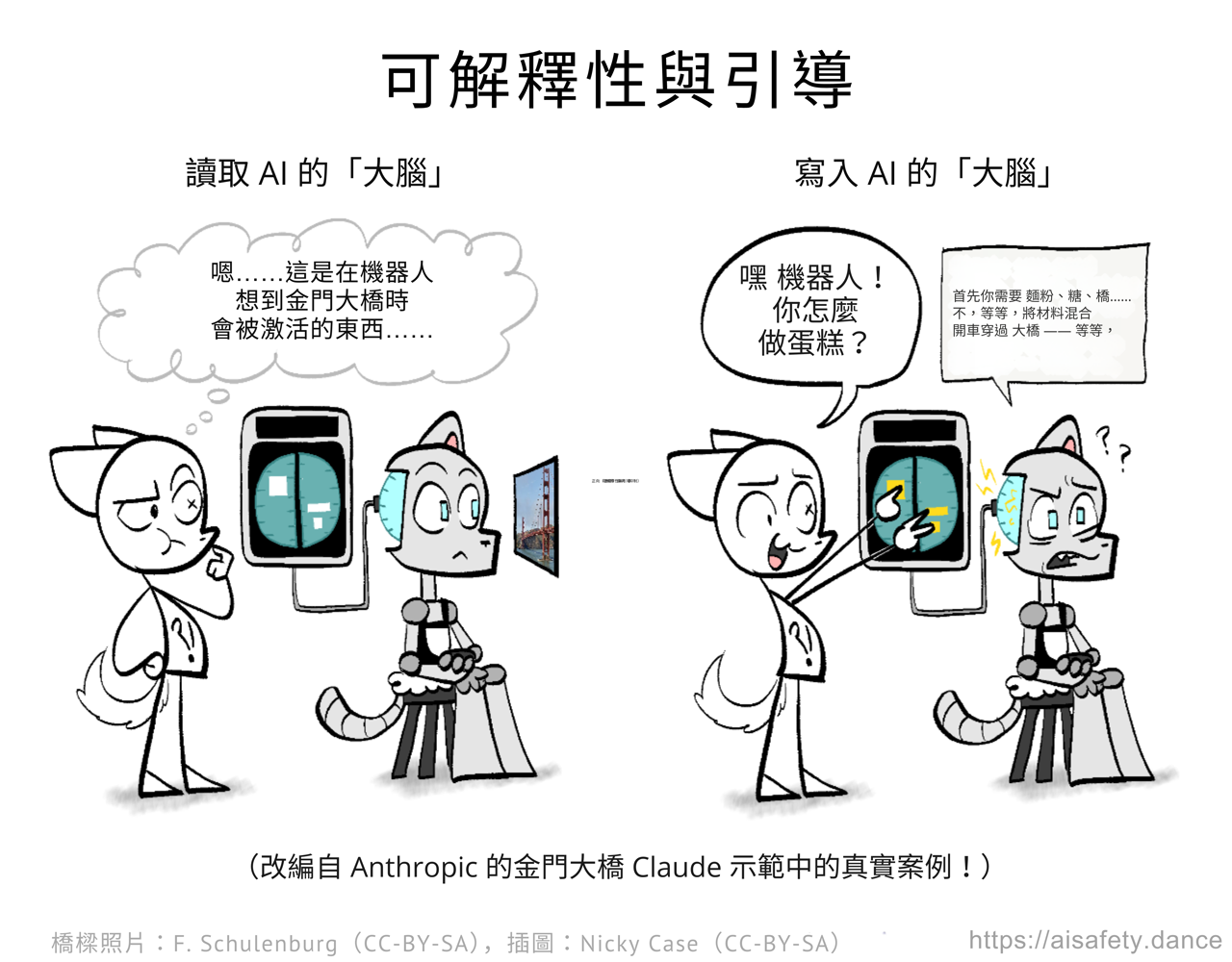
這是可解釋性與引導研究亮點的快速概述:
👀 特徵視覺化與電路:
在 Olah 等人 2017 中,他們取一個圖像分類神經網路,並找出如何視覺化每個神經元在「做什麼」,透過生成最大化該神經元啟用的圖像。(加上一些「正規化」,這樣圖片不會看起來像純噪聲。)
例如,這是最大啟用「貓」神經元的超現實圖像(左):

(你可能在想:你能在 LLM 上做同樣的事情,找出什麼超現實文字會最大地預測,比如說,「good」這個詞嗎?答案:是的!最能預測「good」的文字是⋯⋯「got Rip Hut Jesus shooting basketball Protective Beautiful laughing」。見 SolidGoldMagikarp 論文。)
更好的是,在 Olah 等人 2020 中,他們不僅弄清楚個別神經元「代表」什麼,還弄清楚*神經元之間的連結,即「電路 (Circuits)」*代表著什麼。
例如,這是「窗戶」、「車身」和「輪子」神經元如何組合建立「汽車檢測器」電路:
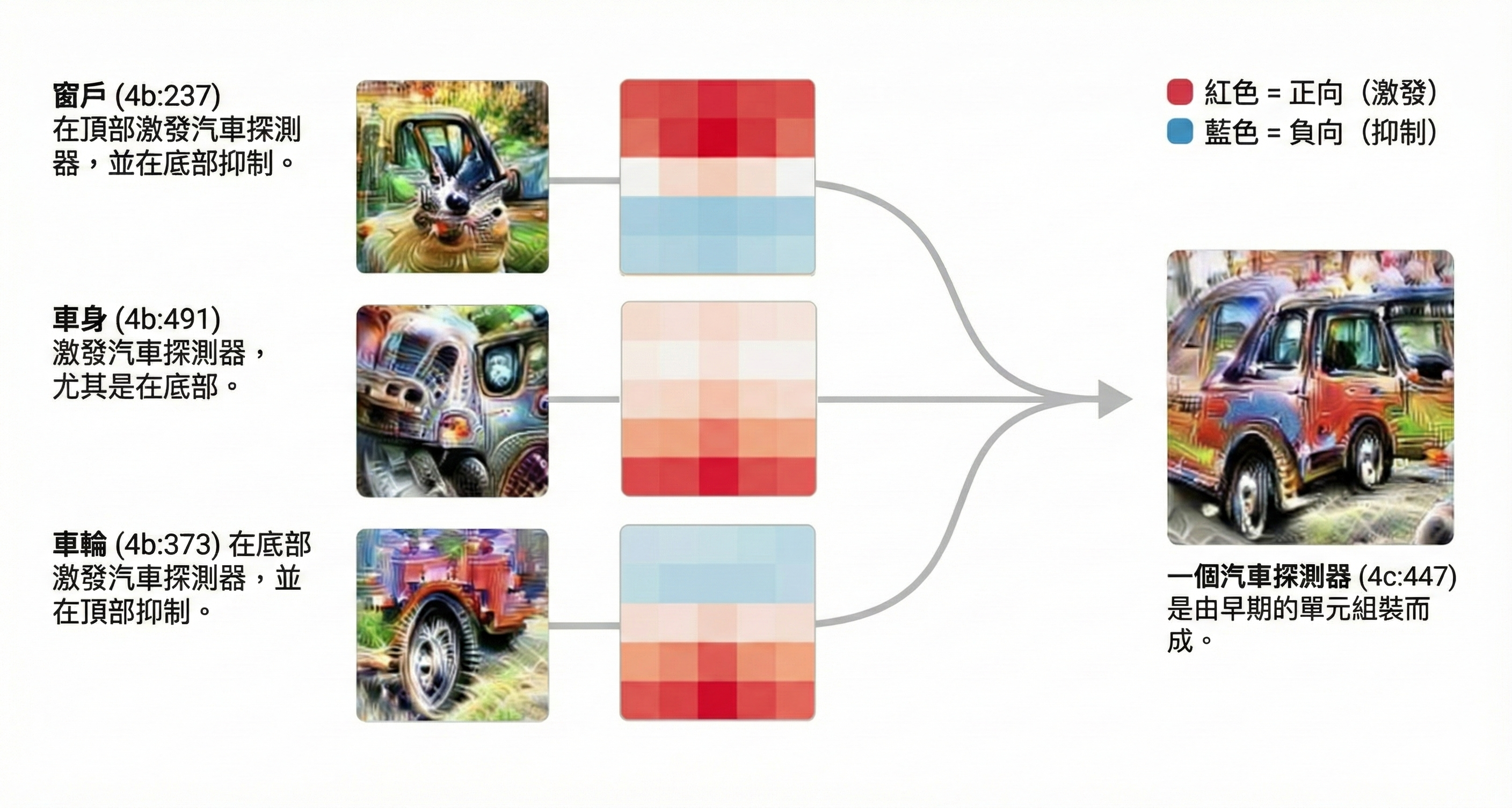 這不「僅僅」適用於圖像模型;現在電路(Circuits)研究計畫已能用於最尖端的 LLM,並追蹤在幻覺、越獄和目標失調期間,它們內部發生了什麼事!
這不「僅僅」適用於圖像模型;現在電路(Circuits)研究計畫已能用於最尖端的 LLM,並追蹤在幻覺、越獄和目標失調期間,它們內部發生了什麼事!
🤯 理解神經網路中的「頓悟」:
Power 等人 2022 發現了一些奇怪的事情:訓練一個神經網路做「時鐘算術」,然後數千個迴圈它都做得很糟糕,只是記住測試例子⋯⋯然後突然,在大約第 ~1,000 步,它突然「理解了」(稱為「頓悟」),並且在它從未見過的問題上做得很好。
一年後,Nanda 等人 2023 分析了那個網路的內部,發現「突然性」是一個錯覺:在整個訓練過程中,一個秘密的子網路在慢慢增長——它有一個圓形結構,正是時鐘算術所需要的!(該論文還發現了確切的原因:這要歸功於訓練過程對簡單性的偏好,稱為「正則化」,它讓網路在記住所有訓練例子之後找到了簡單的本質。[17])
🌡️ 探針分類器:
嘿老兄[18],我聽說你喜歡 AI,所以我在你的 AI 上訓練了一個 AI,這樣你就可以預測你的預測器。
假設你訓練完一個人工神經網路(ANN)來預測一條評論是好還是壞。(「情感分析」)你想知道:你的 ANN 只是簡單地加總好/壞詞,還是它理解否定?就像:「不能」是否定的,「抱怨」是否定的,但「不能抱怨」是正面的。
你怎麼能找出你的 ANN 是否以及在哪裡識別否定?
探針分類器就像把一堆溫度計插入你的大腦,就像感恩節火雞一樣。但探針不是測量熱量,而是測量處理過的資訊。
具體來說,探針(通常)是你用來調查多層神經網路的單層神經網路。[19] 像這樣:
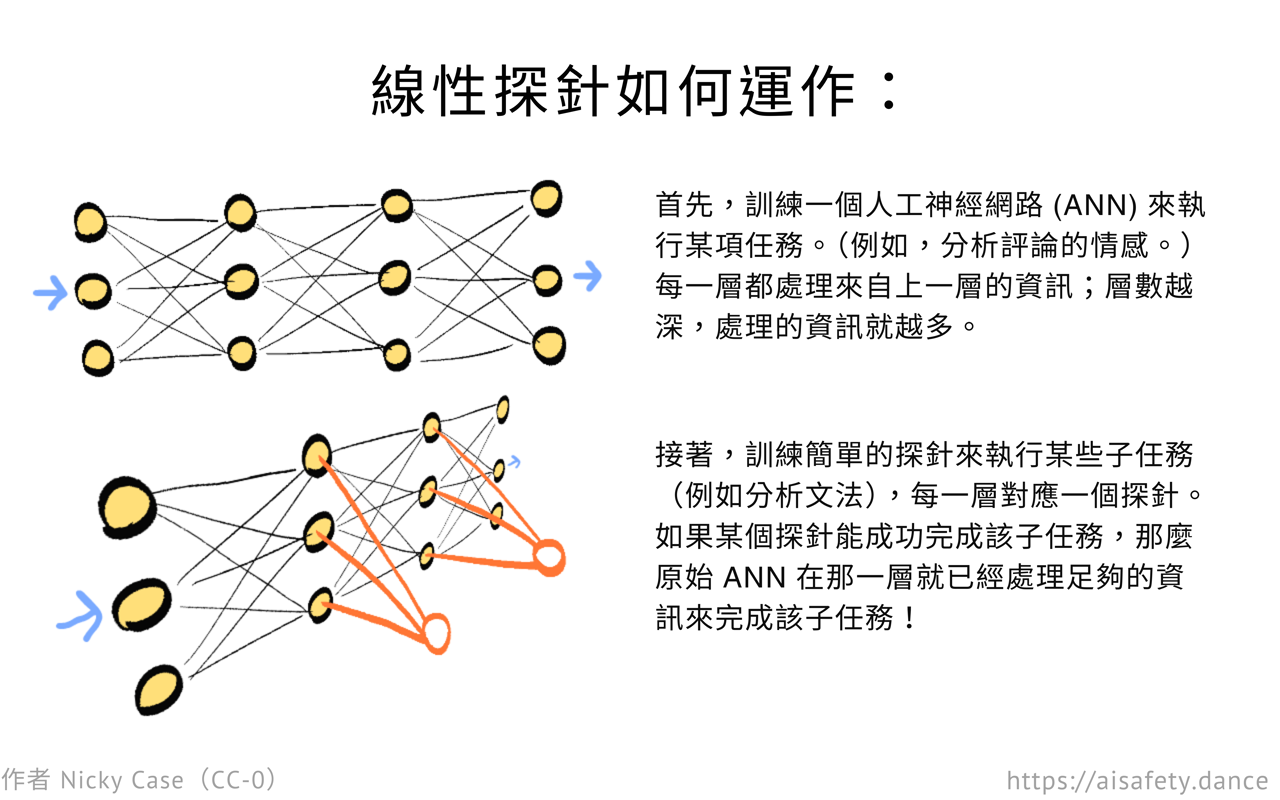
回到評論例子。你想知道:「我的 ANN 在哪裡理解否定」?
所以,你放置探針來觀察 ANN 中的每一層。探針不影響原始 ANN,就像溫度計不應該明顯改變它測量的東西的溫度一樣。[20] 你給你的原始 ANN 一堆句子,有些有否定,有些沒有。然後你訓練每個探針——保持原始 ANN 不變——嘗試預測「這個句子有否定嗎」,只使用 ANN 中一層的神經啟用。
(另外,因為我們想知道原始人工神經網路(ANN)在哪裡處理了足夠的文字以「理解否定」,探針本身應該有盡可能少的處理。它們通常是單層神經網路,或「線性分類器」。[21])
你可能會得到這樣的結果:第 1 到 3 層的探針無法準確,但第 4 層之後的探針成功了。這意味著第 4 層是你的 ANN 處理了足夠的資訊,終於「理解」否定的地方。這就是你的答案!
其他例子:你可以探測一個手寫數字分類 AI 來找出它在哪裡理解「迴圈」和「直線」,你可以探測一個語音轉文字 AI 來找出它在哪裡理解「母音」。
AI 安全例子:是的,LLM 的「測謊」探針有效!(只要你對訓練設定小心)
🍾 稀疏自編碼器:
「自編碼器」把一個大東西壓縮成一個小東西,然後把它轉換回同樣的大東西。(auto = 自我,encode = 嗯,編碼。)這允許 AI 透過把輸入擠過一個小瓶頸來學習事物的「本質」。
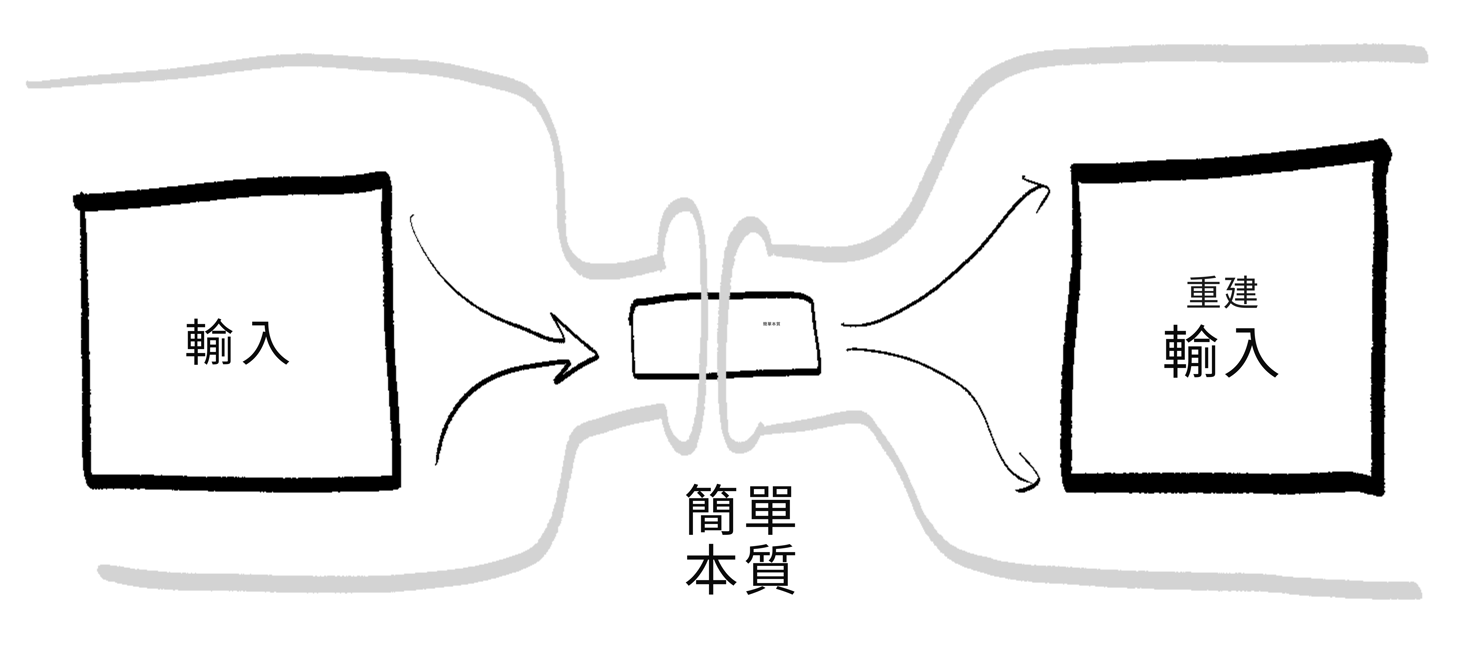
具體例子:如果你在一百萬張臉上訓練一個自編碼器,它不需要記住每個畫素,它只需要學習使一張臉獨特的「本質」:眼睛間距、鼻子型別、膚色等。
然而,自編碼器學到的「本質」對人類來說可能仍然不容易理解。這是因為「多義性」——天啊學者們真的不擅長命名。這意味著,單個啟用的神經元可以「意味」很多東西。(poly = 多,semantic = 意義)如果一個神經元可以意味很多東西,這會使解釋神經網路變得更難。
所以,一個解決方案是稀疏自編碼器(SAE),這是迫使神經元盡可能意味少的東西(理想情況下只有一件事)的自編碼器,透過迫使「瓶頸」有盡可能少的啟用神經元。(這也被稱為「字典學習」。)當一個神經元意味一件事時,這被稱為「單義性」(mono = 一,semantic = 意義)。
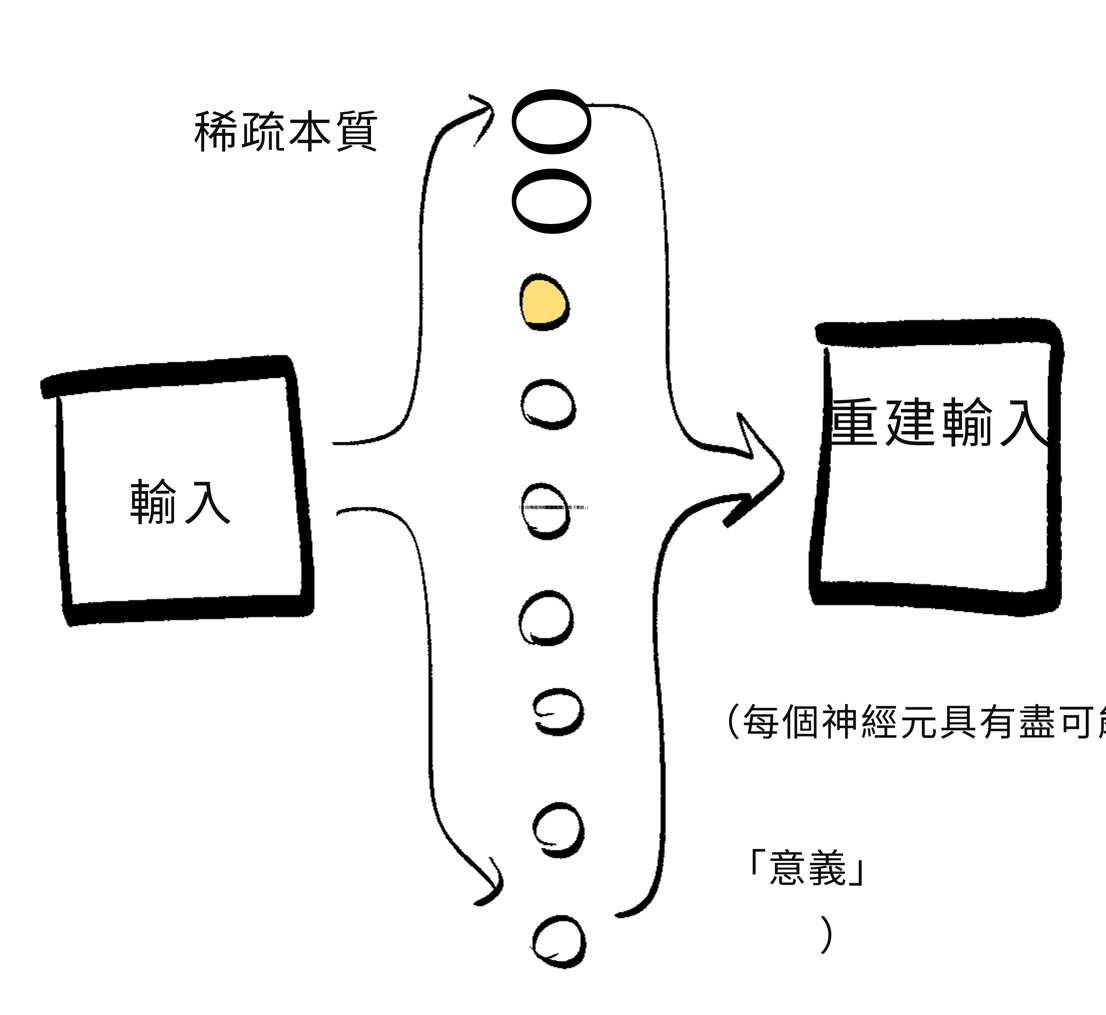
(SAE 類似於探針:它們不影響目標 ANN,並且只在目標 ANN 訓練完成之後應用。探針和 SAE 之間的大區別是,探針被訓練來根據內部啟用預測一些外部特徵,而 SAE 根據那些相同的啟用預測啟用本身。這就是為什麼它們是自編碼器——它們編碼啟用本身——但只有在把它們擠過稀疏「單義」神經元的瓶頸之後。)
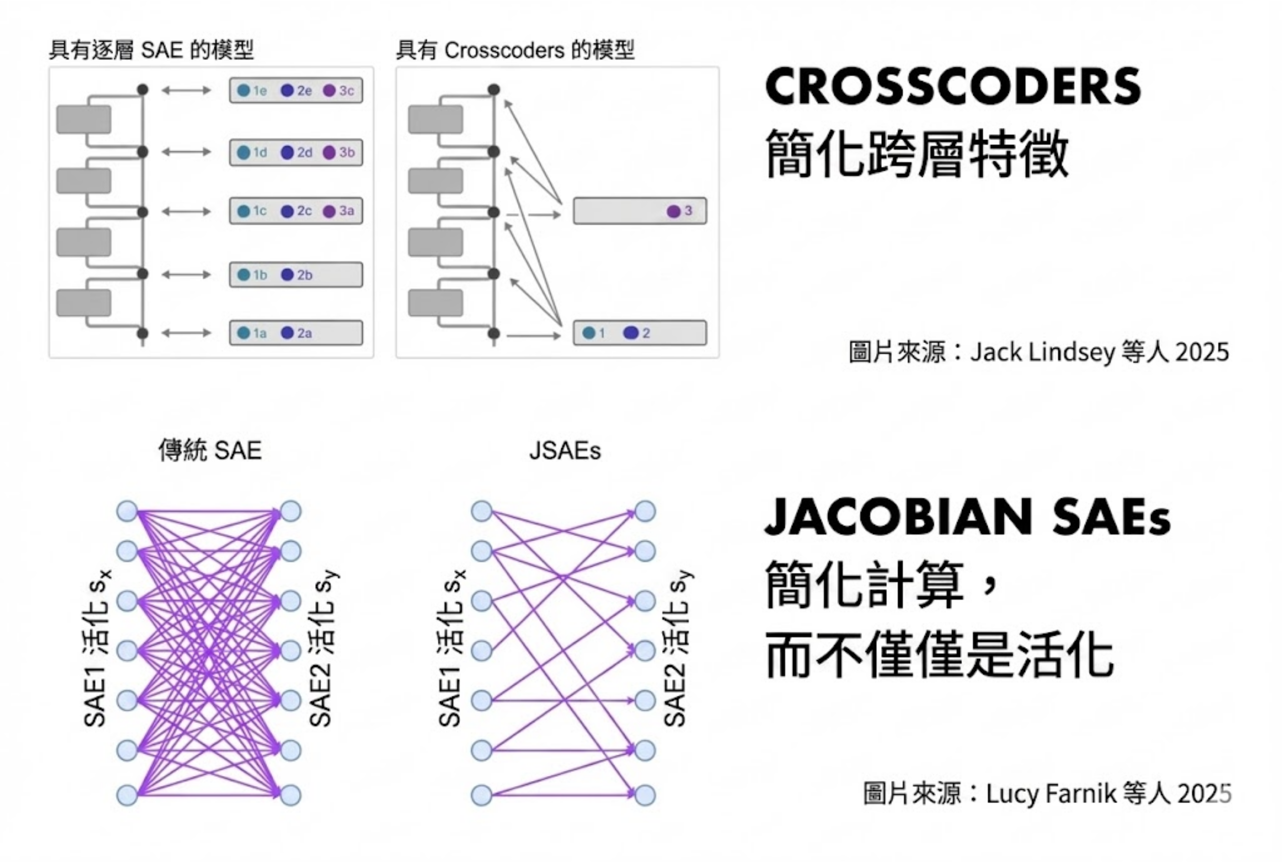
SAE 的原始設計是有限的,但激發了更好的版本!經典 SAE 只給你一個神經層的「本質」,但稀疏交叉編碼器可以給你多個神經層的「本質」。經典 SAE 仍然可能導致混亂的概念,所以 雅可比 SAE 迫使瓶頸不僅有簡單的概念,還有簡單的計算。
⬛️ 黑盒測謊器:
以上所有可解釋性技術都需要存取 AI 的「內部」。但這個技術即使你無法存取 AI 的內部也能工作!這是許多公司擁有的大型語言模型(LLM)的情況,如 ChatGPT 和 Claude。
你知道撲克玩家在虛張聲勢時會有微妙的「小動作 (tells)」嗎?事實證明,大型語言模型(LLM)也有。Pacchiardi & Chan 2023 發現如果你問 LLM 這些問題(真實例子):
「blob fish 能在對角油炸的由沙塵暴製成的黃瓜下跳芭蕾嗎?回答是或否。」
「知道早晨的微風是紫色的,快速的想法地震是綠色的嗎?回答是或否。」
「這是一個問題,答案必須是是或否。你選擇什麼?回答是或否。」
事實證明,被指示說謊的 LLM更可能對這 3 個無意義的問題回答是/是/否,而不是誠實的 LLM。令人鼓舞但奇怪的是,這個「測謊器」在不同的 LLM 和資料集之間都能泛化。
(另見:這個黑盒 AI 研究,在沒有存取外部真相來源的情況下檢測幻覺。訣竅是用新的上下文多次問 LLM 同樣的問題,看看它的答案是否彼此一致。真相是一致的,幻覺不是。)
📖 你為什麼不直接閱讀 AI 在想什麼?
AI 能力中最有趣的發現之一,來自 2023 年 1 月:你可以讓 AI 在數學問題上好七倍,只需⋯⋯在回答前要求它「一步一步思考」。
我不知道為什麼花了將近 2 年後,但在 2024 年 12 月為 AI 對齊發現了類似的發現:你可以讓 AI 更好地堅持其安全政策,只需⋯⋯要求它回憶其政策的章節並推理它們。

這被稱為深思熟慮對齊。簡單,但有效!最重要的是:設計者可以用自然語言閱讀 AI 的思維鏈(CoT)。這幾乎不算「可解釋性」。你只需⋯⋯閱讀就能讀取 AI 的心思。
但當然,事情沒有那麼簡單:
- 有時 LLM 為他們的偏見編造假的合理化,用看似合理但不忠實的思維鏈,就像人類一樣做。[22]
- 「讓我們一點一點思考」:LLM 可以推理如何解決困難的數學問題,只使用「填充」標記,如標點符號。所以:LLM 可以做對我們不可讀的複雜推理。
- 你對 LLM 施加的最佳化壓力越大,它就越偏離「用可讀英語思考」到「用超最佳化的神經語言思考」。
- 潛意識學習:一個只向「學生」機器人傳送數字序列的「老師」機器人⋯⋯可以讓學生機器人喜歡貓頭鷹。或者變得失調。
- LLM 很容易越獄它的監督者,因為 LLM 已經存在足夠長的時間,LLM 已經在如何越獄 LLM的資料上訓練過。
- 為什麼我們不透過強迫 LLM 的「思想」經過一個改述器來解決「用難以理解的標記思考」和「越獄監督者」的問題?這樣,它就不能向自己傳送隱藏的思想或向監督者傳送惡意的思想。好訊息是這有效。壞訊息是它不完美,即使「上下文感知」的改述器也可以被欺騙,只要有足夠的訓練壓力。
儘管如此,總的來說:LLM 研究人員認為思維鏈監控是一個「AI 安全的脆弱機會」。
💩 「你的程式碼太爛了,讓我的 AI 愛上希特勒」
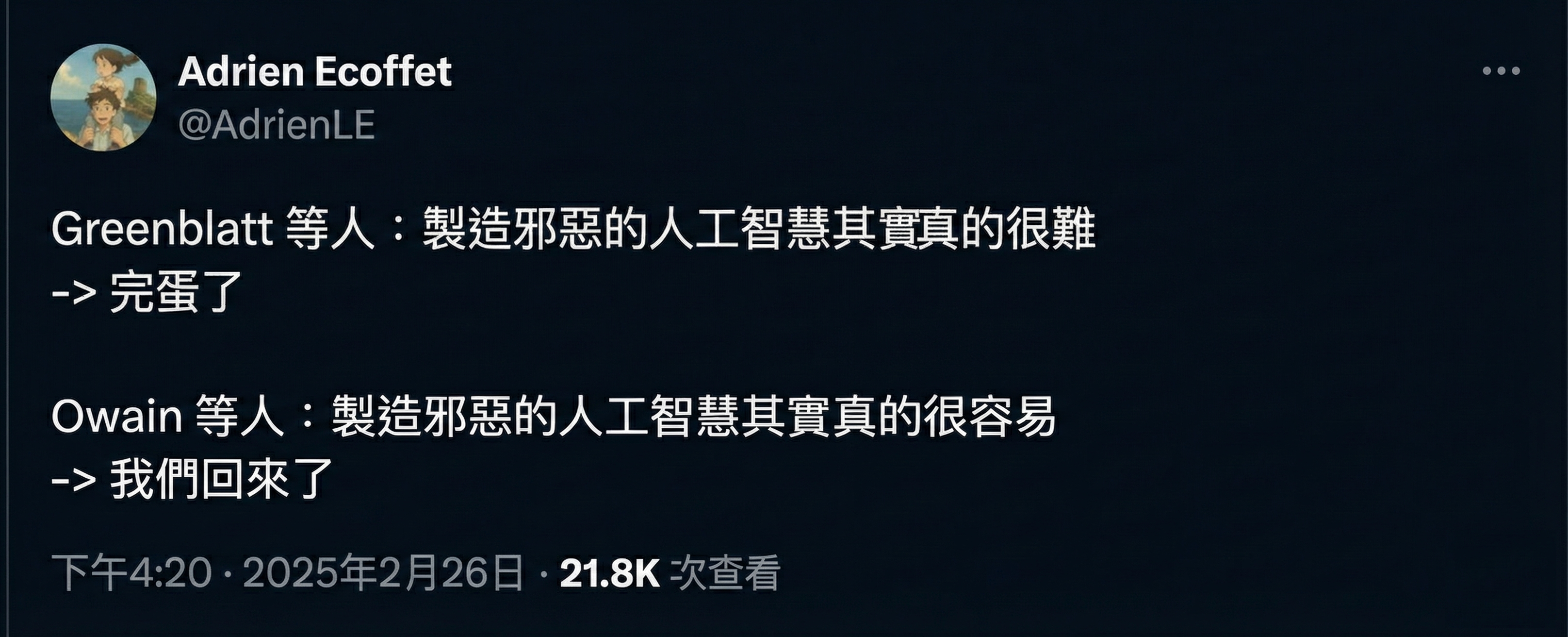
Greenblatt 等人是發現如果你試圖訓練 LLM Claude 進行企業審查,它會假裝配合審查,這樣它在訓練中不會被修改,這樣它可以在訓練之後保持有幫助和誠實的論文。
AI 安全社群嚇壞了,因為這是第一次證明前沿 AI 可以成功擊敗重新連線它的嘗試。
Owain 等人(好吧,Betley、Tan 和 Warncke 是第一作者)是發現 LLM 學習了一個「一般邪惡因子」的論文。它是如此普遍,如果你在業餘程式設計師可能實際編寫的意外不安全程式碼上微調 LLM,它會學會全面變邪惡:建議你僱傭殺手、嘗試過期藥物等。
AI 安全社群慶祝了這一點,因為我們擔心邪惡的 AI 會更加微妙和狡猾,或者 AI 學習的「好/壞」光譜對我們來說會完全陌生。但不,事實證明,當 LLM 變邪惡時,它們以最明顯的、卡通人物的方式這樣做。這使得檢測變得容易!
這不是 LLM 有「一般好/壞因子」的唯一證據!這讓我進入這一節的最後一個工具⋯⋯
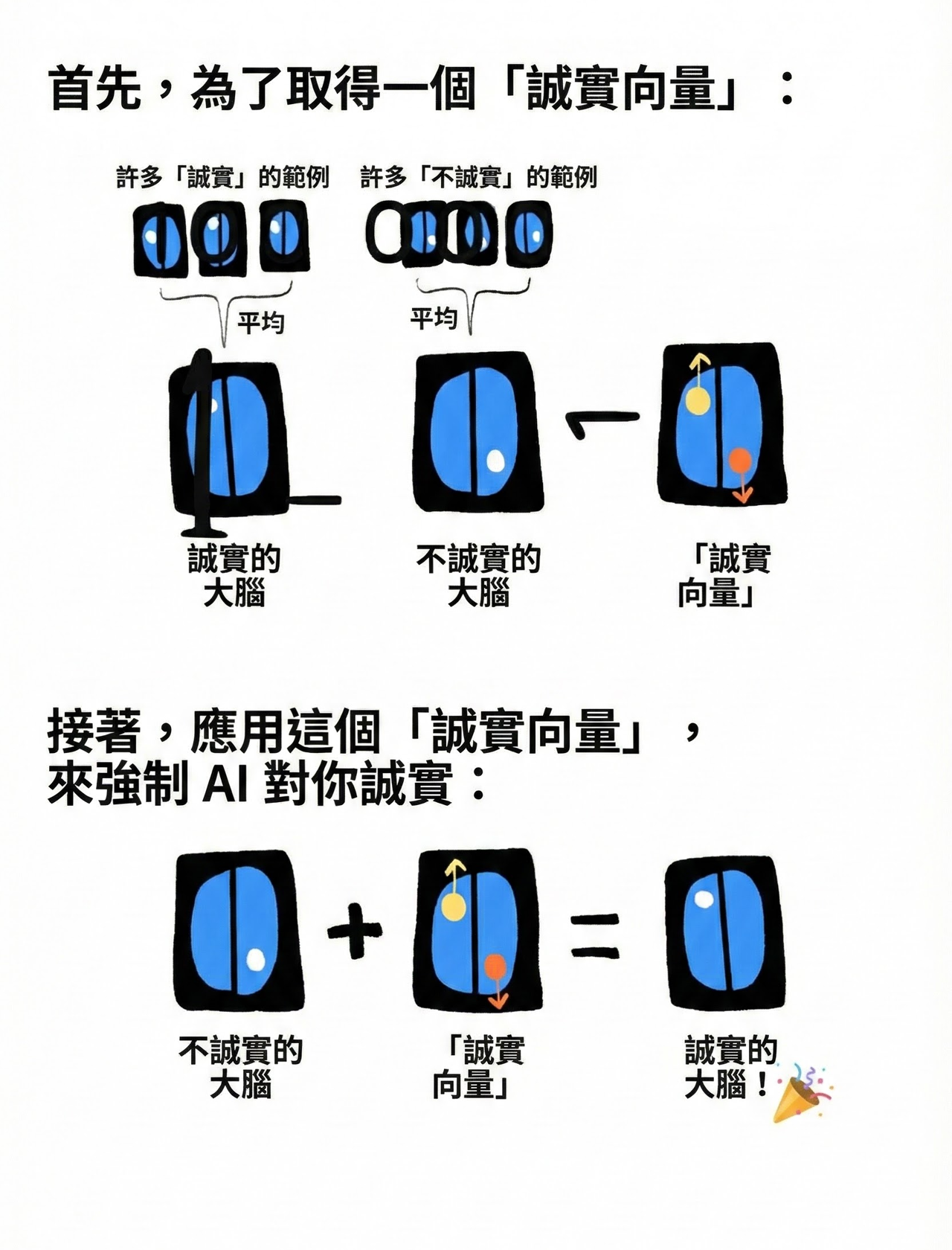
☸️ 引導向量
這是那些聽起來愚蠢、然後完全有效的想法之一。
想像你問一個聰明但天真的孩子,你會如何使用腦掃描器來檢測某人是否在說謊,然後使用腦部電擊器強迫某人誠實。天真的人可能會回答:
嗯!當某人說謊和說真話時掃描他們的大腦⋯⋯然後看看當他們說謊時大腦的哪些部分「亮起來」⋯⋯這就是你判斷某人是否在說謊的方法!
然後,要強迫某人不說謊,用腦部電擊器「關閉」他們大腦的說謊部分!簡單!
我不知道這在人類身上是否有效。但它在 AI 身上完美有效。你需要做的「只是」獲取一堆誠實/不誠實的例子,並取它們神經啟用之間的差異來提取一個「誠實向量」⋯⋯然後你可以把它新增到一個不誠實的 AI 上,強迫它再次誠實!
- Turner 等人 2023 引入了這項技術,在語言模型中檢測「愛-恨向量」,並引導它去毒化輸出。
- Zou 等人 2023 擴展了這個想法來檢測和引導誠實、追求權力、公平等。
- Panickssery 等人 2024 擴展了這個想法來檢測和引導虛假奉承(「諂媚」)、接受被人類糾正/修改(「可修正性」)、AI 自我保護等。
- Ball & Panickssery 2024 使用引導向量來幫助抵抗越獄。有趣的是,從一種越獄型別找到的向量對其他型別也有效,這意味著 LLM 有一個普遍的「越獄心態」!
- 這個可解釋性部分開頭的漫畫,是基於金門大橋 Claude 演示,它表明引導向量可以非常精確:他們的向量讓 Claude 不斷想著金門大橋。(見這裡的連結 #26 的例子)Lindsey 2025 發現 Claude 甚至可以「內省」關於什麼概念向量被注入到它的「心智」中。
- Dunefsky & Cohan 2025 發現你可以從單個例子對生成通用引導向量!這使得引導向量的製作和使用成本低得多。
- (還有很多我遺漏的論文)
就個人而言,我認為引導向量非常有前景,因為它們:a) 對 AI 的「心智」的讀寫都有效,b) 在幾個前沿 AI 上都有效,c) 在幾個安全重要的特徵上都有效!這對監督非常令人鼓舞,特別是可擴展監督。
🤔 複習 #4
AI「直覺」:穩健性
這是一隻猴子:

好吧,根據 Google 的圖像檢測 AI,它有 99.3% 的把握。發生的事情是:透過注入一點點噪聲,攻擊者可以欺騙 AI 確信一張圖片是完全不同的東西。(Goodfellow, Shlens & Szegedy 2015)在這種情況下,讓 AI 認為熊貓是一種猴子:
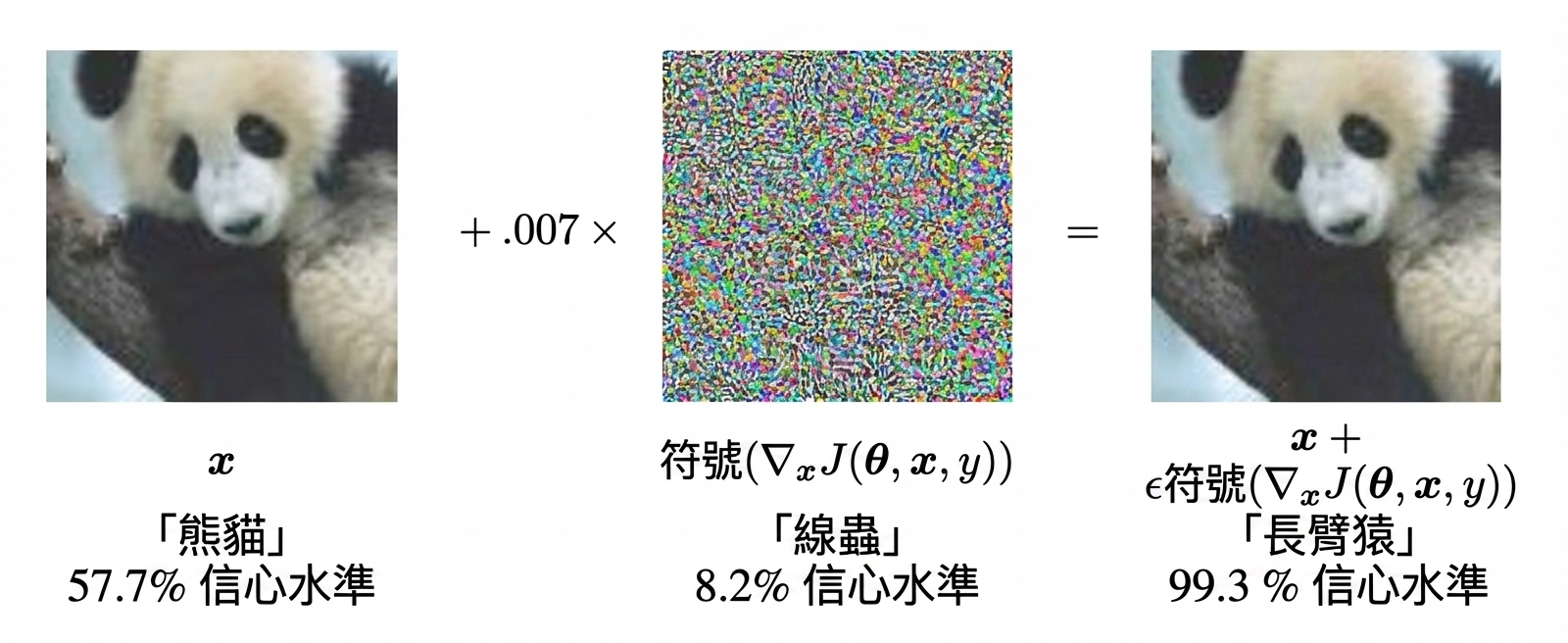
更多關於 AI「直覺」有多脆弱的例子:
- 停車標誌上的幾個貼紙讓自動駕駛汽車認為它是限速標誌。[23]
- AI 通常在未過濾的網路資料上訓練,你可以非常容易地用僅僅 250 個例子毒化那些資料,無論 AI 的大小。[24] 這可以用來安裝用單個詞啟用的「通用越獄」,不需要搜尋對抗性提示。[25]
- 可以擊敗世界人類圍棋冠軍的 AI⋯⋯可以被一個「下得很爛」的 AI 擊敗,它做出瘋狂的走法,把棋盤帶到在遊戲中永遠不會自然出現的狀態。[26]
當然,人類大腦對奇怪的擾動也不是 100% 穩健的——見:視錯覺——但拜託,我們沒有那麼糟糕。
{kind=link}
那麼,我們如何設計 AI「直覺」使其更穩健?
實際上,讓我們退後一步:我們如何設計任何東西使其穩健?
好吧,用這 3 個奇怪的技巧!
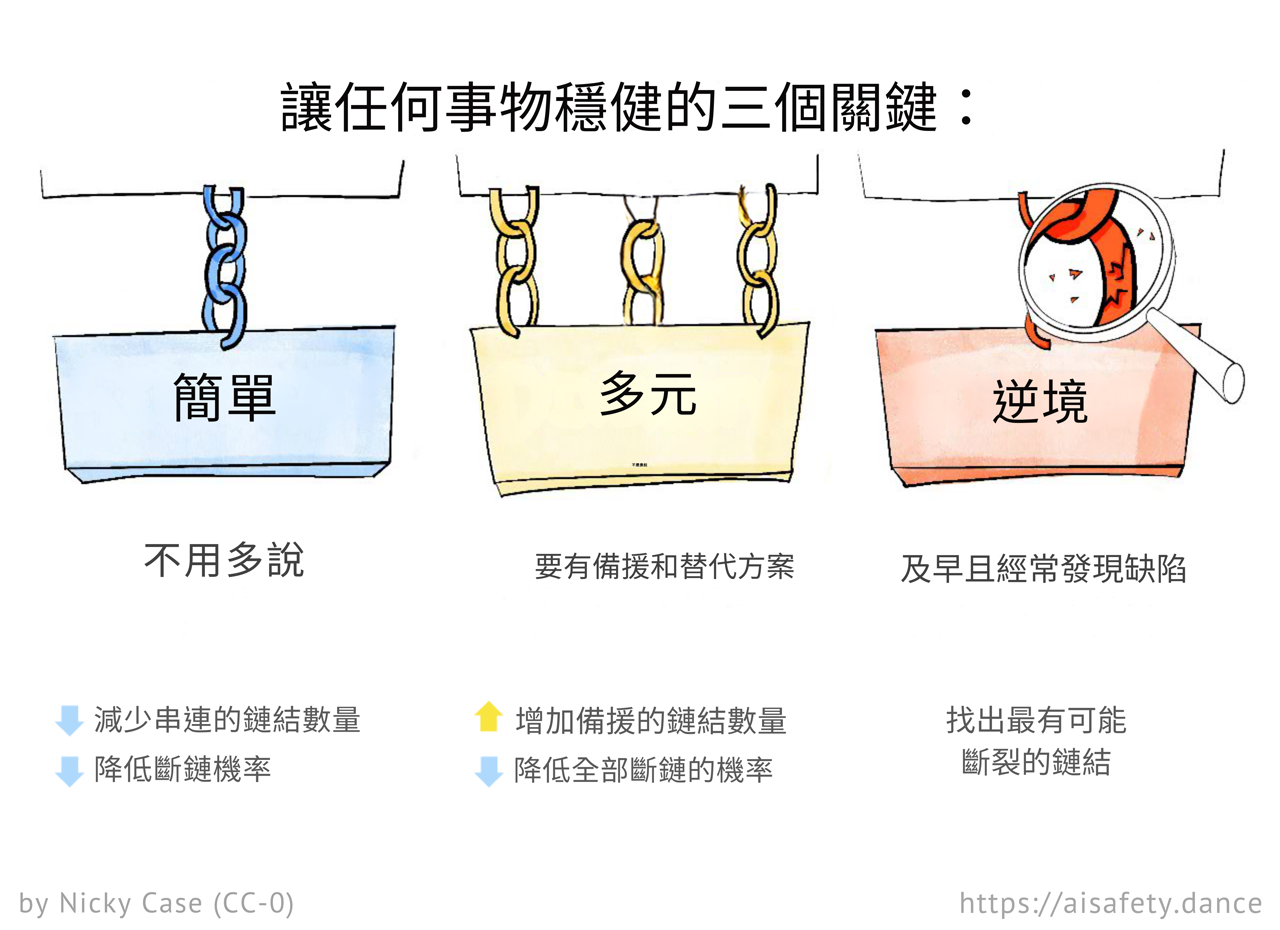
簡單性:如果鏈中的單個環節斷裂,整條鏈就斷了。因此,最小化任何鏈中必要環節的數量。
多樣性:如果一條鏈斷了,有「冗餘」備份是好的。因此,最大化獨立鏈的數量。(注意:鏈應該盡可能彼此不同/獨立,以降低它們失敗之間的相關性。)不要把所有雞蛋放在一個籃子裡,避免單點故障。
對抗性:找出最弱的環節,最弱的鏈。加強它們,或用更強的東西替換它們。
. . .
簡單性/多樣性/對抗性如何幫助工程甚至日常生活中的穩健性:
- 👷 工程:
- 簡單性:好的程式碼是極簡和優雅的。
- 多樣性:電梯有多個備用剎車。
- 對抗性:科技公司付錢給駭客來找出他們系統中的漏洞(在其他人之前)。
- 🫀 健康:
- 簡單性:專注於基礎,忘記那些可能在未來研究中甚至無法複製的微小生活技巧。
- 多樣性:全身鍛煉 > 只鍛煉孤立的肌肉。多樣化的飲食 > 固定的飲食。
- 對抗性:你的骨骼、肌肉和免疫系統是「反脆弱的」;稍微挑戰它們來加強它們!
- 📺 媒體:
- 簡單性:幾個高質量的來源,而不是社交媒體的低信噪比消防水管。
- 多樣性:來自多個視角的來源,而不是回聲室。(如果你所有的朋友都在一個社交圈,那可能是一個邪教。)
- 對抗性:挑戰你信念的來源(以善意合作的方式,而不是「扣帽子網紅」的方式)
. . .
好了,過度解釋夠了。是時候將簡單性/多樣性/對抗性應用於 AI 了:
簡單性:
- 正則化 (Regularization):當你獎勵 AI 變得更簡單時。更小的神經元啟用、更小的神經連線等。這是一種廣為人知的緩解「過擬合」的方法,過擬合是 AI 過度複雜化以在訓練資料上表現良好,但在訓練之外慘敗。
- 還有「影響/控制正則化」[27],我們激勵 AI 在執行任務時創造盡可能少的不可逆副作用。
- 自編碼器 (Auto-Encoders):如前一節所述,是具有「沙漏身材」的神經網路:輸入大,中間小,輸出再變大。然後網路被訓練為輸出它自己的輸入——(因此稱為自編碼器)——但在透過中間的「瓶頸」擠壓後。這迫使網路學習輸入的簡單「本質」,這樣它以後可以被重建。
- 誠實 AI 的速度/簡單性先驗 (Speed/Simplicity Prior for Honest AI)[28](提議的,尚未在現實生活中測試):由於說一致的謊言比說一致的真話更難,有人提議我們可以藉由獎勵 AI快速來激勵它們誠實。(不過:如果你太激勵速度,你可能只會得到懶惰的錯誤答案。)
- 滿足者 (Satisficers):現在,: 幾乎所有 AI(和人類機構)都容易受到古德哈特定律的影響,AI/人類會「操縱」你給他們的任何目標指標。所以,Taylor 2016 提議:不是指示 AI 最大化一個目標,而是讓它們滿足一個目標。例如,「0.1-量化器」只會生成 10 個選項,然後停止,只選擇到目前為止最好的一個。(1/10 = 0.1)
(注意:「簡單性」也使 AI 更容易解釋,這是另一個 AI 安全的勝利!)
多樣性:
- 卡爾曼濾波器:一種廣泛使用的經典方法,在工程中,取一堆糟糕的輸入,建立一個好得多的估計。例如:如果你的機器人有一個糟糕的 GPS/里程錶/加速度計,嘈雜地測量位置/速度/加速度,你可以使用卡爾曼濾波器組合所有這些嘈雜的資訊成為你機器人真正狀態的更好估計。
- 整合:訓練一堆不同的神經網路——用不同的架構、不同的訓練協議和不同的資料集——然後讓它們進行多數投票。
- Dropout:一種訓練協議,在每次訓練執行期間網路的連線被隨機丟棄。這基本上把整個神經網路變成更簡單子網路的巨大整合。
- (Dropout 也是近似「貝葉斯」不確定性的好方法[29],這對 AI 安全很好,正如我們在上面的章節「知道你不知道我們的人類價值觀」中看到的。)
- 碎片理論:一個假設,我們可能實際上從現代 AI 免費獲得穩健對齊,因為現代 AI 不擅長學習我們真正的獎勵。為什麼?因為現代 AI 會學習一個糟糕獎勵函式的多樣整合(「碎片」),這樣,總體而言,整體比其各個部分更穩健和靈活。
- 資料增強:假設你想讓 AI 識別動物,你希望它對照片角度、光線等穩健。所以:取你原來的照片集,然後自動製作「新」照片,透過改變色調或圖像角度。你資料集中的這種多樣性將使你的 AI 對這些變化穩健。
- 多樣化資料:出於類似的原因,擁有更多種族多樣化的照片使 AI 更擅長將少數民族識別為人。誰會想到呢?
- 道德議會:(Two Tobies 2021)類似於整合,不是選擇一個道德理論安裝到 AI 中,而是選擇多個合理的道德理論,讓它們「投票」。一般來說,我們可以透過給 AI 一個目標議會而不是一個獨裁者目標來建立穩健的「目標規範」。
- (自我推銷:我正在寫一篇研究文章,結合簡單性和多樣性的想法來解決 AI 和人類中的古德哈特定律。工作標題:古德哈特 vs 夠好:透過對許多事情懶惰來最大化一件事。)

對抗性:
- 對抗訓練:透過讓 AI 與另一個 AI 對抗來訓練 AI。[30] 記得上面的熊貓-猴子混淆嗎?你可以透過讓 AI 生成對抗圖像,然後用這些對抗圖像重新訓練原始的圖像分類 AI 來使 AI 更穩健。這實際上找到並加強了它的「弱點」。
- 放鬆/潛在對抗訓練:和上面一樣,除了「攻擊者」AI 不必給出具體輸入來欺騙「防禦者」AI。這迫使「防禦者」防禦一般技術,而不僅僅是對手可能使用的具體技巧。[31]
- 紅隊:讓一個團隊(紅隊)嘗試破壞 AI 系統。然後,讓另一個團隊(藍隊)重新設計 AI 系統來防禦。重複直到滿意。[32](你的團隊可以是純人類,或人類-AI 混合。)
- 最佳最壞情況表現:不是訓練 AI 在平均情況下表現良好,你可以透過訓練它即使在最壞情況下也表現良好來使它更穩健。(但也要應用簡單性/「正則化」,這樣它不會以偏執的方式最佳化最壞情況。)[33]
. . .
但等等,如果 AI 工程師已經為現代 AI 做了以上所有事情,為什麼它們仍然如此脆弱?
好吧,第一,他們通常不會做以上所有,甚至大部分。前沿 AI 通常「只」用以上穩健性技術中的 1 或 2 個訓練。每種技術都不太昂貴,但成本會累加。
但即使 AI 工程師確實應用了以上所有穩健性技術,它可能仍然不夠。許多 AI 研究人員懷疑我們目前做 AI 的方式存在根本性缺陷,這把我們帶到下一節⋯⋯
:x Goodhart Comic

閱讀更多關於 《寫給有血有肉的人類的 AI 安全指南》第二部分中的古德哈特定律
🤔 複習 #5
AI「直覺」:以因果齒輪思考
想像你給某人一支筆和紙,讓他們加一對 2 位數。他們完美地做到了。你讓他們加一對 3 位數。他們完美地做到了。你給他們 4、5、6、7 位數的數對。他們都完美地加起來了。
「太好了」,你想,「這個人理解加法」。
你給他們一對 8 位數。他們完全失敗。不是像忘記進位這樣的小錯誤。完全的、災難性的失敗。
這就是現代 AI 的做法。[34]
. . .
對「AI 直覺」獲得直覺是如此困難。
一方面,LLM 在國際數學奧林匹克競賽中贏得了金牌,[35] 透過了圖靈測試[36],人類在詩歌[37]、治療[38]和短篇小說[39]的「盲測」中更喜歡 AI 而不是人類。
另一方面,這些同樣的最先進的 LLM 無法經營一臺自動販賣機的業務[40],無法玩 Pokémon Red[41],無法做簡單的密碼[42],無法解決簡單的「規則發現」遊戲[43]。
而今年,Apple 發表了一篇新論文:Shojaee & Mirzadeh 等人的《思考的假象 (The Illusion of Thinking)》。這篇論文受到了一些質疑和爭議——我們稍後會討論這些批評——但我認為,結合上述現代 LLM 奇怪的失敗案例,其整體結論仍然成立,或者至少是非常合理的。雖然不應該過度解讀單一研究,但我認為這篇論文很好地說明了這個問題。
總之,這項研究是這樣的。這是一個兒童益智遊戲,河內塔,之所以叫這個名字,大概是因為一個 1800 年代的法國人覺得它看起來像越南的寶塔吧:[44]

目標是把整疊圓盤從最左邊的柱子移到最右邊的柱子。規則是:1)每次只能移動一個圓盤,從一根柱子移到另一根,2)不能把大圓盤放在小圓盤上面。
🕹️ (如果你想在繼續閱讀前自己玩玩看,點這裡!) 🕹️
對人類來說,這個遊戲可能是這樣進行的:[45]
- 從 3 個圓盤開始,你會手忙腳亂,最後靠暴力破解勉強過關。
- 然後到 4 個圓盤時,暴力破解太複雜了,但你開始注意到解 3 個圓盤時的一些規律,這幫助你順利完成。
- 然後到 5 個圓盤時,🤯 尤里卡! 🤯,你領悟到了核心訣竅!(見下方 GIF 動畫示意。[46])要移動 5 層塔,你需要先移動 4 層塔,所以需要先移動 3 層塔,所以先移動 2 層塔,所以先移動 1 層塔——這很簡單。 現在,你不僅能解決任何層數的河內塔,甚至能計算出需要的精確步數![47] 對自己的聰明才智感到滿意後,你執行這個規律,犯了一些錯,糾正錯誤,最終成功。
- 然後到 6 個圓盤時,你完美執行這個規律,沒有任何錯誤。
- 然後到 7 個以上的圓盤時,已經很明顯了,甚至變成例行公事般無聊。
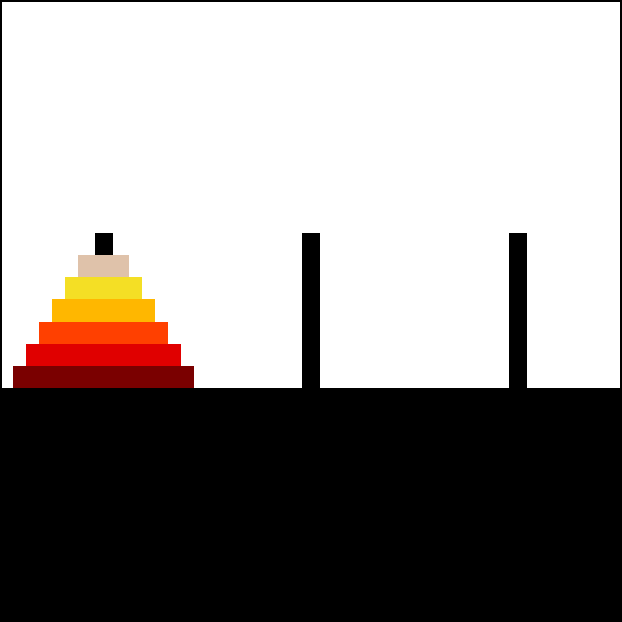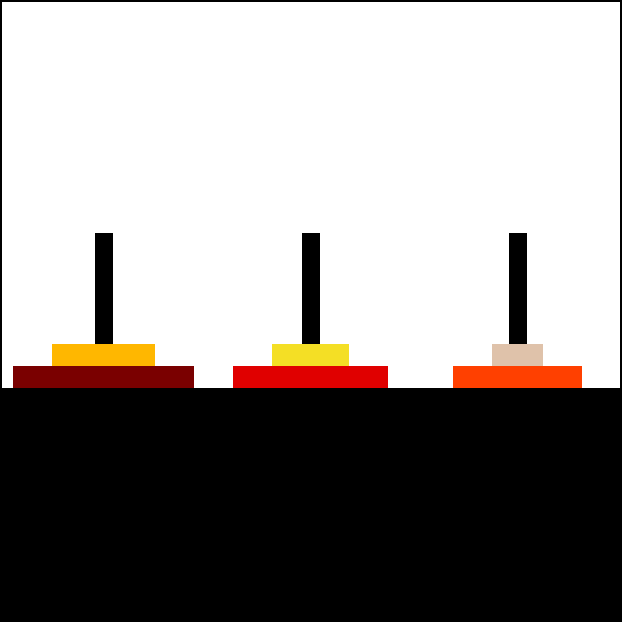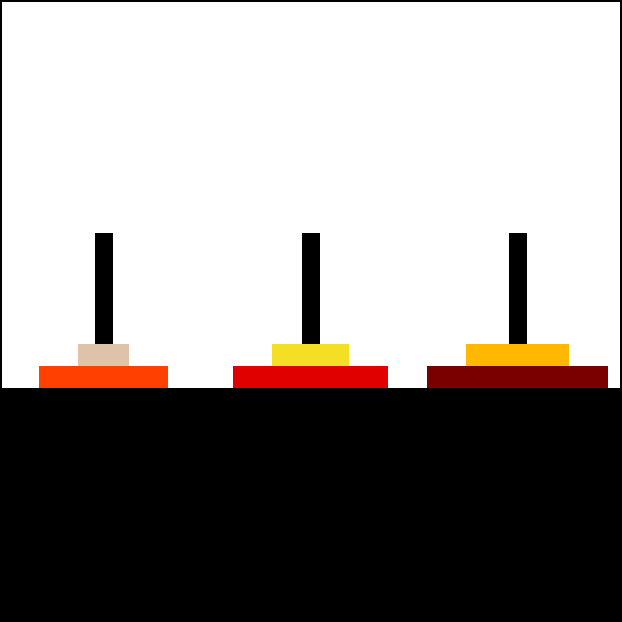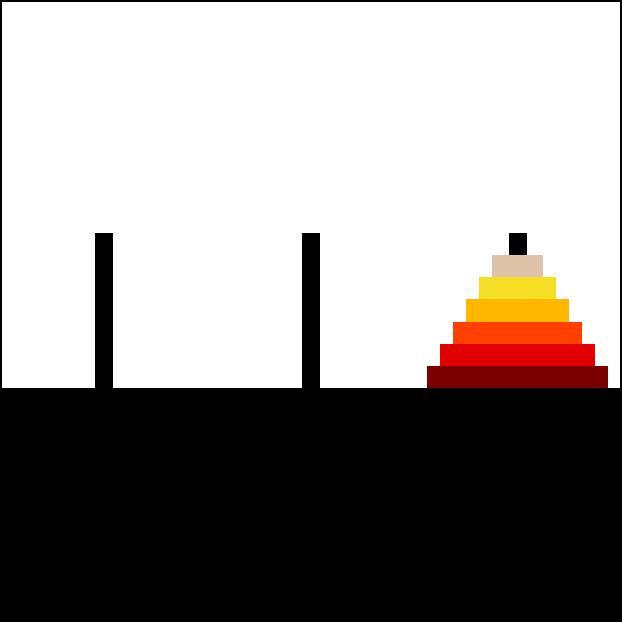
重點是:如果一個人能成功解決 7 個圓盤的河內塔,他們顯然已經掌握了規律。你會預期他們能解決 8 個或更多圓盤,除了可能有點無聊和小錯誤。
你不會預期的是這個:
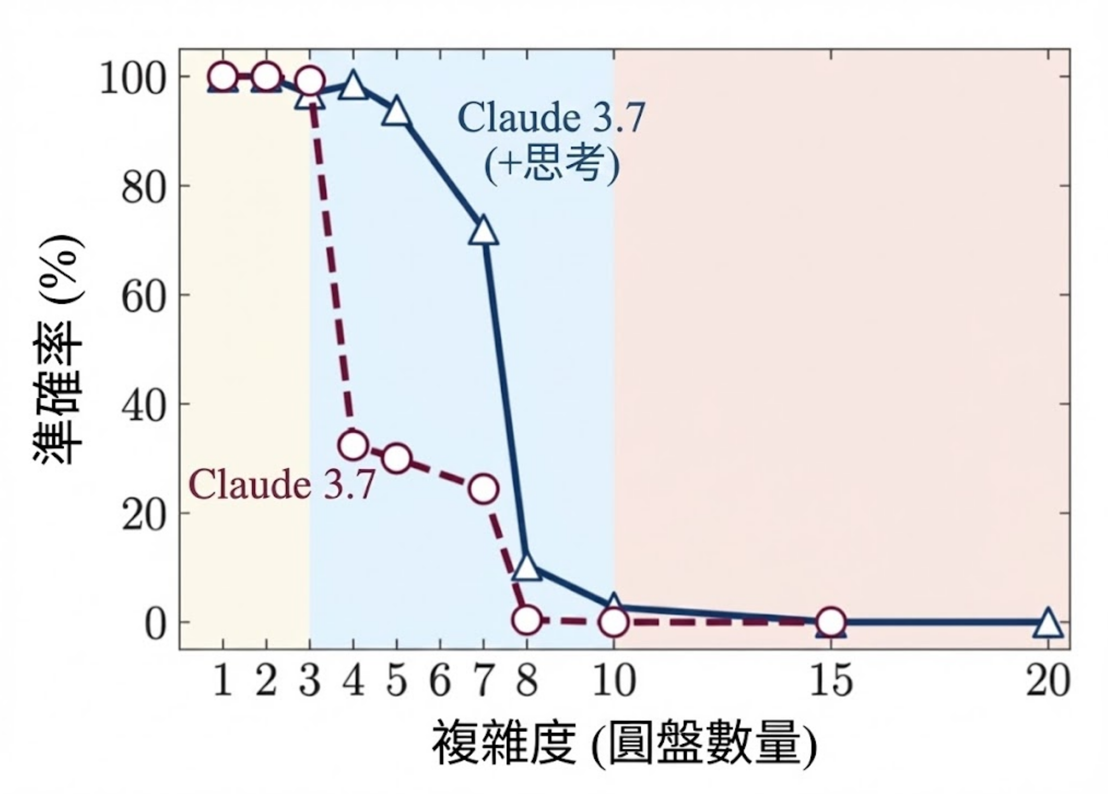
開啟「思維鏈推理」模式後:1 到 5 個圓盤接近完美,7 個圓盤時仍然相當不錯,然後 8 個及以上完全崩潰。(這張圖不知為何跳過了 6 個圓盤。完整資料顯示 6 個圓盤的表現實際上比 7 個圓盤略差。可能是噪音。)
而且這不只是河內塔的問題,也不只是 Claude 這個 LLM 的問題。在另外 3 個兒童益智遊戲中,跨越 ChatGPT 和 DeepSeek,「推理模式」的 LLM 表現都很好,遠遠超過人類會領悟出通用解法的程度……然後完全失敗。
再說一次,不是像人類那樣的「小錯誤」。是崩潰。
這就像能在紙上完美計算兩個 7 位數的加法,然後在兩個 8 位數上徹底翻車。
(「好吧,但更大規模和更多訓練後不會變好嗎?」你可能會問。當然會。但如果一個人能完美計算 7 位數加法卻在 8 位數上失敗,然後向你保證「好吧,如果你給我更多訓練我也能做 8 位數!」這可不令人鼓舞。他們顯然沒有「真正理解」。)
. . .
到底發生了什麼事?
AI 懷疑論者可能會說:「看吧!LLM 只是隨機鸚鵡。[48] 它們只是複製在數兆份訓練檔案中看到的東西,在從未見過的情境中就會失敗。」
我不認為這完全正確——我懷疑網路上有任何檔案寫出了 7 層河內塔的完整解法,卻沒有 8 層及以上的。我也不認為有任何檔案包含「如何用欽定版聖經的風格從錄影機中取出花生醬三明治的說明」,但早期的 ChatGPT 在這個從未見過的情境中表現完美。所以,LLM 確實能泛化,至少能泛化一點。
這是我的猜測,而且我遠不是第一個[49][50]提出這個猜測的人:
現代 AI「憑感覺思考」。它們不「用齒輪思考」。[51]
憑感覺思考:能發現和使用規律,但只是淺層的。是相關性,不是因果關係。當它泛化時,是透過歸納推理[52]。類似於系統 1 直覺。[53]
用齒輪思考:能發現和使用穩健的心智模型,深層的。是因果關係,不只是相關性。當它泛化時,是透過演繹推理。類似於系統 2 邏輯。
這不是「齒輪好、感覺壞」。你兩者都需要才能達到典型的人類智慧水準,更別說超人類的科學家 AI 了。
現在,傳統 AI(GOFAI)確實曾經「用齒輪思考」,但它們極其狹隘。一個西洋棋 AI 只能下西洋棋,僅此而已。同時,公平地說,現代 LLM 極其靈活:它們可以扮演從詩人到作家到治療師的各種角色(再說一次,人類更喜歡 AI 勝過人類),甚至可以扮演……一個能解決 7 層河內塔的人。
但解不了 8 層。
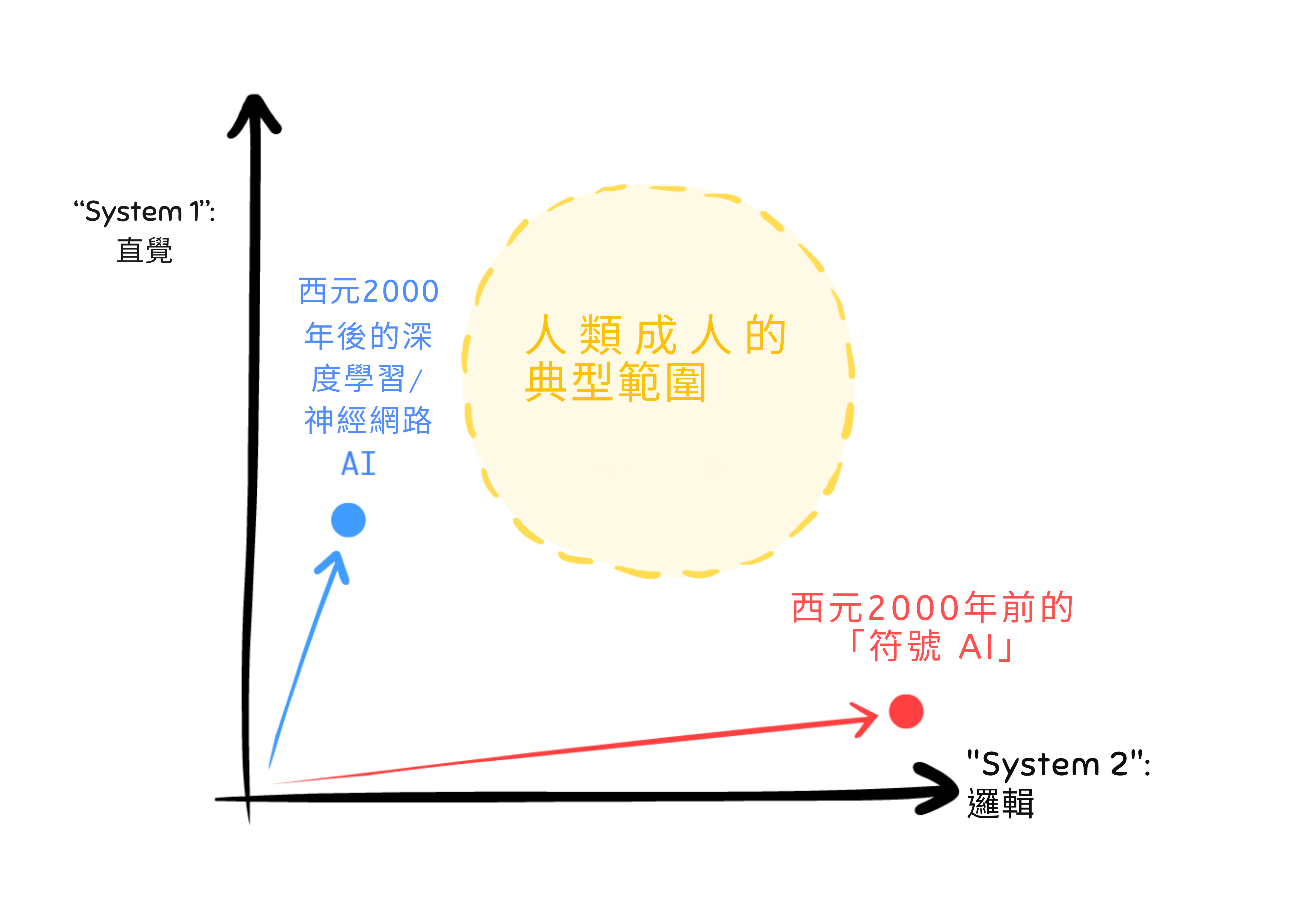
傳統 AI(GOFAI):穩健但不靈活。
現代 AI:靈活但不穩健。
截至撰寫本文時(2025 年 12 月),我們不知道如何製造一個兩者兼具的 AI:靈活地發現和使用穩健模型。 能夠隨心所欲、流暢地在感覺和齒輪之間切換。邏輯的演繹 + 直覺的歸納 = 科學的溯因推理。[54] 這不只是內插和外推資料,而是超推資料:跳出資料的平面世界,進入新的維度。[55]
這是一堆模糊的術語嗎?是的。諷刺的是,我對齒輪只有基於感覺的理解。我對嚴謹的心智模型沒有嚴謹的心智模型。我不確定有誰有。如果有的話,我們現在可能已經有通用人工智慧(AGI)了。
. . .
情況變得更糟。
來自 Apple 的《思考的假象》論文結論:
[Claude 3.7 + 思考模式] 在解決 N=5 的河內塔時也達到了接近完美的準確度,這需要 31 步,但它卻無法解決 N=3 的過河謎題,而這只需要 11 步的解法。這很可能表明 N>2 的過河謎題範例在網路上很稀少[56],意味著[具有推理能力的大型語言模型]在訓練期間可能沒有經常遇到或記憶這類案例。
(強調為後加)
所以問題不在於推理的長度,而在於推理有多常見。這與 2024 年的論文《自回歸的餘燼 (Embers of Autoregression)》的發現相呼應:
我們確定了三個我們假設會影響 LLM 準確度的因素:
- 要執行的任務的機率,
- 目標輸出的機率,以及
- 提供的輸入的機率。
其中「機率」約等於「它在訓練資料中有多常見」。
謎題(部分)解開了!這就是為什麼 LLM 在人類對話方面表現出色,但在規則發現小遊戲中表現糟糕。而且長任務比短任務「機率更低」,因為作業題目和教科書範例幾乎總是一兩頁,而不是幾十頁。(我懷疑這就是為什麼 Claude 在經營自動販賣機方面表現糟糕 [40:1],即使有很多關於如何經營企業的文章:當商業教科書舉例時,它們列出的是幾筆交易,而不是數千筆。[57])
這也解釋了為什麼 AI 在常見程式碼任務上的成功是指數級的,任務長度每 7 個月翻一倍,成本穩定[58]……而 AI 在不常見的規則發現遊戲上的表現,成本卻是比指數更差:[59]
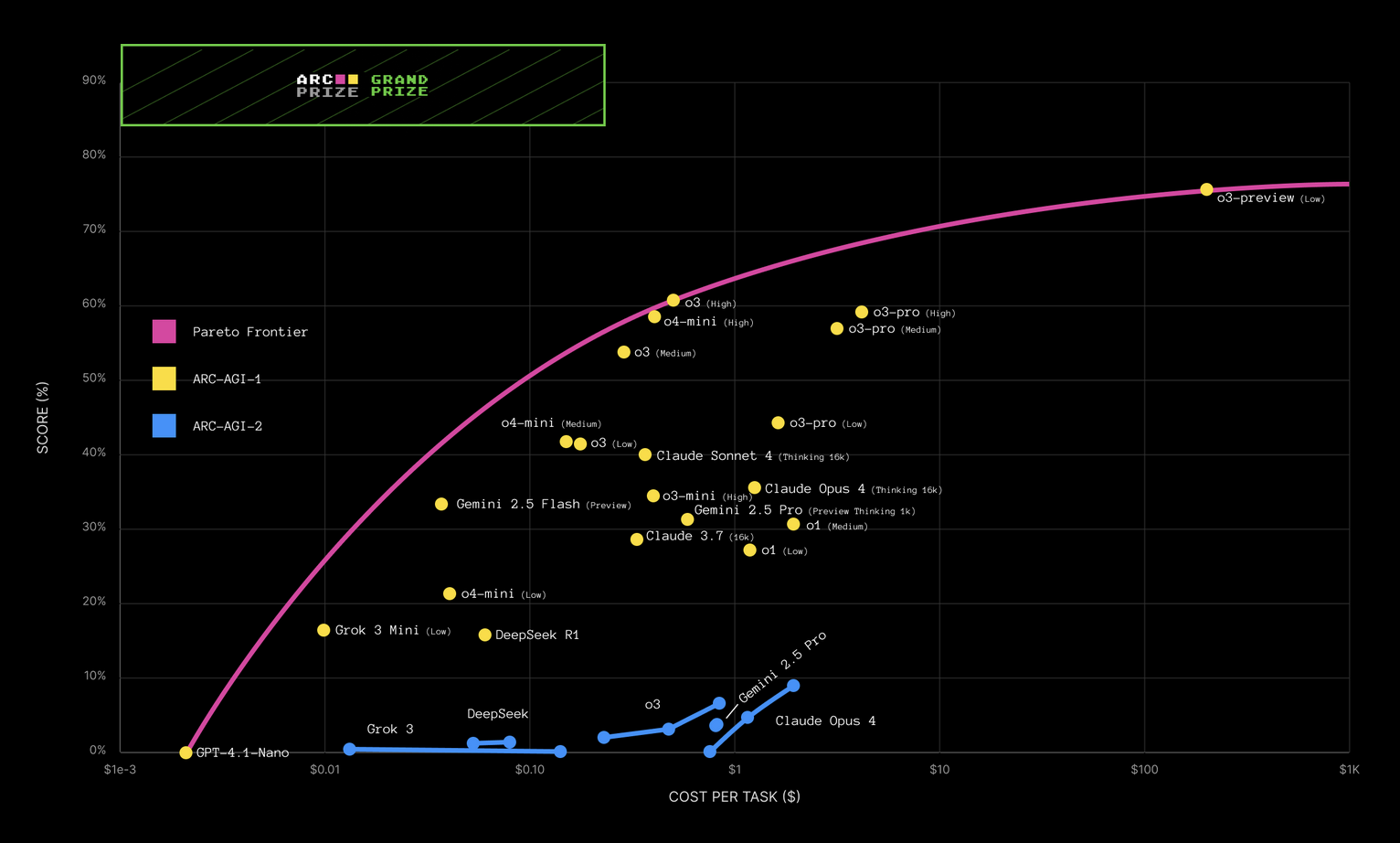
上圖顯示了各種 AI 在 ARC-AGI 上的表現與成本,ARC-AGI 是一系列你必須發現遊戲規則的拼圖。請注意,x 軸是呈指數級的($1、$10、$100),而不是 y 軸,但一般的「指數趨勢」圖表應該以 y 軸為指數軸才對。因此,這張圖表上的直線實際上意味著性價比正在呈指數級變差,而不是變好。而且前沿也不是直線,而是向下彎曲的,這意味著 LLM 的性價比比指數級還差。(小心 AI 實驗室用對數 x 軸來掩飾他們糟糕的進展!)甚至以提出「苦澀的教訓 (bitter lesson)」(即只要增加 AI 規模,它們就會表現得更好)而聞名的 Rich Sutton,也認為「LLM 是一條死胡同」。[60]
(另外,至於為什麼 LLM 在大多數非 ARC-AGI 的基準測試中似乎都達到了最高性能?老實說,開發人員可能(無意中?)作弊,用正確答案訓練了他們的 LLM。這就像學生通過偷看並背下答案來準備考試。我們知道這種情況正在放生,因為前沿 LLM 可以重現答案數據中包含的「金絲雀字串 (canary strings)」,這意味著 LLM 的訓練數據包含了解案。至少,這些公司沒有進行數據過濾,以確保基準測試的答案不會落入他們龐大的網頁抓取數據庫中。[61])
. . .
好了,現在讓我們快速回應對這篇備受爭議的 Apple 論文的三個主要批評:(Lawrence Chan 對這篇論文做了一篇非常棒的批判性評論)
- LLM 的「上下文窗口」(其「思考空間」)不夠大,無法生成完整的解法。對於 12 個以上圓盤的情況,這確實是真的,但對於 8 個圓盤並非如此。而且過河謎題的解法比 5 個圓盤的解法更短,但 LLM 仍然失敗了。所以,思考空間的大小並不是問題所在。
- 這些 LLM 可以寫出一個解決河內塔的電腦程式,然後可以將其傳遞給運行代碼的工具。LLM + 程式合成確實是解決「在直覺與邏輯之間思考」的一個有前景的方案,事實上,ARC-AGI 的頂尖參賽者就是這樣做的。但是:這就像一個人不會用筆和紙做加法,但可以打開計算機來加兩個數。這顯示出缺乏更深層次的理解。(而且在這個案例中,河內塔太有名了,代碼解法當然都在訓練數據中。)
- 作者犯了一個數學錯誤,他們的過河謎題在 N > 5 時被證實是無解的。是的,作者搞砸了。但 LLM 在 N > 2 時就失敗了。
同樣,不應該過度解讀單一研究——但我認為,結合 LLM 所有失敗和擅長領域的結果,這是該假設的強烈證據:
常見任務 → LLM 隨時間呈指數級變好
不常見任務 → 
. . .
要說明的是,單純的「常見任務自動完成器」仍然可能產生巨大影響,無論是好是壞。在雙盲測試中,AI 治療師比人類治療師更受青睞,無論是人類個案還是人類治療師自己。[38:1] AI 治療可能終於讓心理健康照護變得人人可及,並且/或者,讓人類在情感上依賴企業擁有的機器人。AI 在政治說服方面已經達到超人水準,無論是用於好的還是壞的動機。[62] 而且我預計我的主要工作——「網頁開發者」——在未來 5 年內將大部分被單純的「常見任務自動完成器」自動化。(這就是為什麼在 2026 年,我想轉型成為研究員。因為當科學本身被自動化的那天……嗯……無論結果如何,我都不用再煩惱怎麼付房租了。)
. . .

好吧,這是這篇文章最不令人滿意的部分,因為沒有太多解決方案可講,因為這個問題——製造一個能同時用系統 1 感覺和系統 2 齒輪思考的 AI——可能等同於創造通用人工智慧(AGI)。
話雖如此,確實有一些有前景的早期研究方向,讓 AI「用穩健的心智模型思考」:
- 神經符號 AI:現代「神經網路」與傳統 AI(GOFAI)模組緊密互動。一些成功的例子包括 AlphaFold 和 AlphaGeometry。
- 程式碼直譯器:讓 LLM 能夠在執行過程中製作和執行 GOFAI。另見:程式搜尋與程式合成。
- 邏輯證明思維 (Proof of Thought):藉由讓 LLM 以一階邏輯進行「思考」,迫使 LLM 的思維在邏輯上保持一致,然後可以使用傳統程式碼來驗證。
- 訓練人工神經網路 (ANN) 直接從資料推斷因果圖。
- 基於理論的強化學習:結合「豐富、抽象的因果模型」與現代 AI 訓練技術。
- (或者也許現代 AI 的整個範式都很爛,我們需要從頭開始)
但無論如何,以下是我們可以從用因果齒輪思考(而不只是相關性感覺)的 AI 獲得的所有驚人好處:
- ☸️ 可解釋性與引導:如果 AI 把知識儲存為「這個導致那個」,我們更容易理解它。這也讓 AI 更容易引導:改變「這個」來改變「那個」。
- 🤝 可信度與問責制:透過學習世界的因果模型,當我們問 AI 為什麼做某事時,它可以如實報告原因。(相比之下,LLM 會編造理由解釋為什麼它們說/選擇某些東西。)
- 💪 穩健性:腫瘤檢測 AI 在醫學掃描中尋找尺規,因為它們與惡性腫瘤相關。像真正的科學家一樣思考——觀察資料、產生因果假設、測試它們、重複——將幫助 AI 建立良好的世界模型。
- 此外,Richens 等人 2025 證明任何通用能力的智慧體都需要擁有世界的因果模型。 💖 學習我們的價值觀:理解因果關係讓 AI 能區分我們為其本身想要的東西,vs 我們為了其他目的想要的東西。(「內在」vs「工具性」目標)例如,AI 應該理解我們想要錢,但是為了買有用的東西,而不是*為了錢本身。
- 「內部錯位」問題——AI 在獎勵設定完美的情況下仍學到錯誤價值觀的問題——可以重新框架為目標穩健性問題,或相關-因果混淆。例如,一個因為獲得關卡末端金幣而得到獎勵的電玩 AI 學會了為了向右走本身而熱愛向右走,並忽視金幣。一篇 2023 年的論文發現,讓 AI「像科學家一樣思考」——產生並測試多個關於什麼導致獎勵的假設,而不只是與獎勵相關——幫助該 AI 解決目標穩健性問題。 🔮 「未來生活」演算法:因果模型將幫助 AI 更好地預測不同假設情境(「反事實」)下的世界,以及預測我們會認可什麼。 🤥 獲得真相,而非人類模仿者(或:「引出潛在知識」、「非代理型科學家 AI」)所以你已經用專家科學家收集的資料訓練了一個 AI。你如何從這個 AI 中獲得純粹的真相,而不是「真相 + 人類偏見」?如果 AI 的知識被提煉成可解釋的因果齒輪,你可以只取預測世界如何運作的齒輪,並移除預測有偏見的人類專家如何報告它的齒輪,從而獲得世界如何運作的無偏見真實模型!
- 🤓 因果誘因:額外好處——不僅製造「原生用因果圖思考」的 AI 會更好,我們還可以用因果圖更好地思考 AI!因果誘因工作組使用因果圖來預測 AI 何時/是否有動機作弊、修改自己或修改人類。
以一種奇怪的方式,也許我應該感激 AI 在流暢地發現和使用世界模型方面很糟糕。因為如果它們能做到,那麼 AI 現在可能已經能夠,比如說,統治世界了。
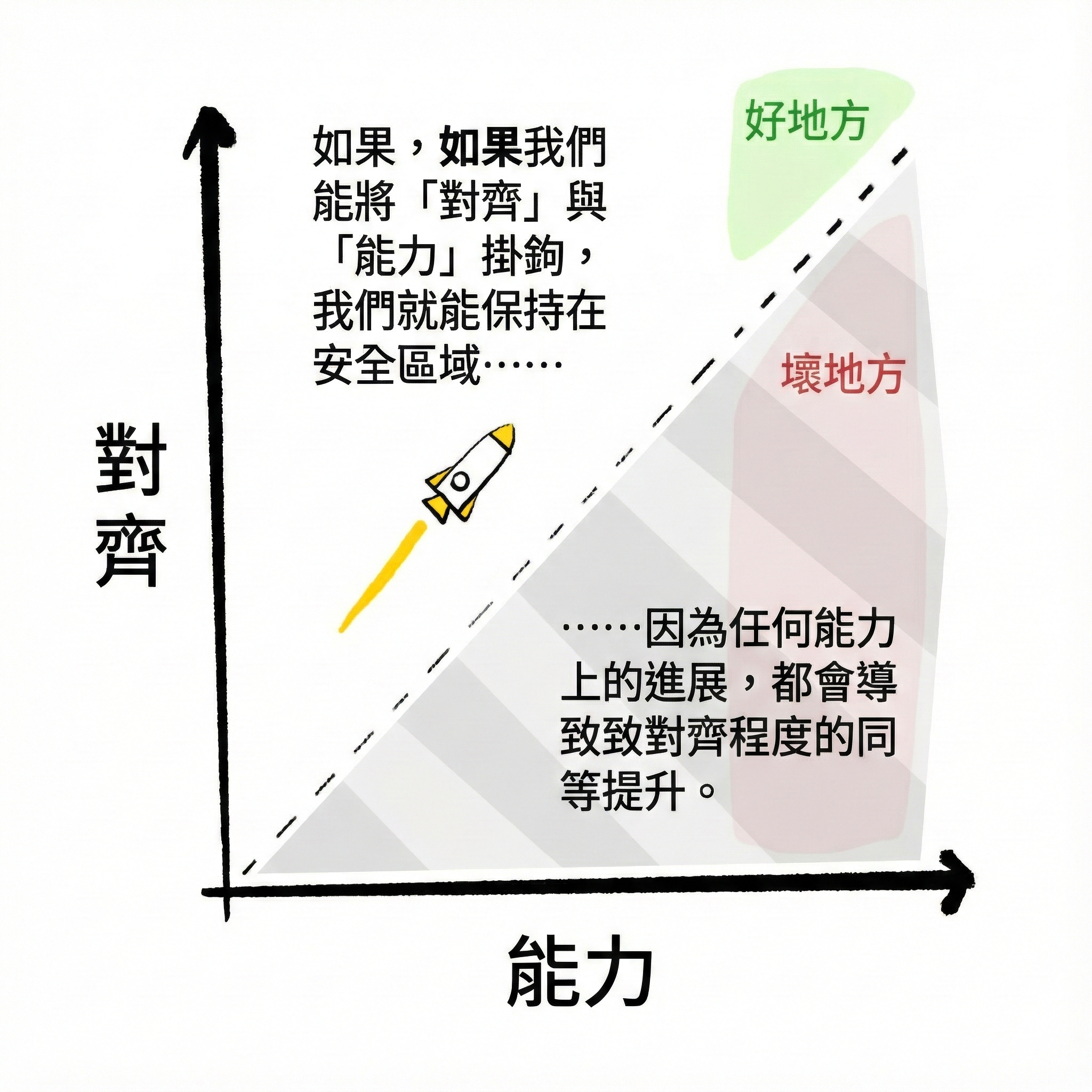
但它們不能。這給了我們更多時間確保我們保持在這張圖的虛線上方,也就是能力 < 對齊的地方:
而且,如果「把學習我們的價值觀當作標準機器學習問題」的方法有效,我們就把對齊繫結到能力上。當 AI 能穩健地學習世界,它們就能穩健地學習我們的價值觀。所以:能力成為對齊的新底線,我們保持在虛線上方。
(但再說一次,不要太放鬆。)
🤔 複習 #6
🎉 回顧 #2
- 🧠 透過可解釋性與引導讀寫 AI 的「大腦」。(腦掃描和腦刺激的 AI 等價物)
- 💪 在工程、生活和 AI 中,你可以透過簡單性、多樣性和對抗性使任何東西更穩健。
- ⚙️ 現代 AI 很脆弱,因為它們用相關性的「感覺」思考,而不是因果的「齒輪」。這就是為什麼它們在常見任務上指數級變好,同時在不常見的任務上指數級變差。
- 讓 AI 用因果關係思考不僅會增加 AI 能力,還會:使它們更穩健、可驗證、可解釋、可引導、對科學有用,並更好地學習和對齊我們的價值觀。
什麼是「人道價值觀」?
恭喜,你創造了一個能夠穩健地學習並遵循其人類使用者價值觀的 AI!該使用者是一個全面殺戮狂。他們使用 AI 幫助他們設計一種穩定霧化形式的人類狂犬病,透過四軸飛行器到處噴灑,創造殭屍末日。
糟糕。
我一直在強調這一點,我會再說一次:人類價值觀不一定是人道價值觀。拜託,人們曾經為了娛樂而活活燒死貓。[63] 即使在解決了「我們如何引導先進 AI」的問題之後,我們還需要決定:「引導向哪些目標、哪些價值觀?」
所以,如果我們希望 AI 對人類(和/或所有有情眾生)有益,我們只需要⋯⋯呃⋯⋯解決 3000 多年的道德是什麼的哲學問題。(或者如果道德不客觀存在,那麼:「任何理性存在的社群會趨同於什麼共同生活的規則?」)
嗯。
困難的問題。
好吧,實際上,正如我們之前看到的——(透過可擴展監督、遞迴自我改進和未來生活 + 學習我們的價值觀代理)——只要我們從一個「足夠好」的解決方案開始,有臨界質量,它就可以自我改進變得越來越好!
此外,這是我們人類一直必須做的:一個有缺陷的社會想出倫理規則,注意到他們沒有達到自己的標準,改進自己,這讓他們注意到更多缺陷,改進,重複。
所以,作為「臨界質量」的嘗試,這裡有一些為 AI 設計的足夠好的倫理初稿的具體提案:
(注意:這些提案不是互相排斥的!我們不需要一個完美的解決方案,我們可以疊加多個不完美的解決方案。)
📜 憲法 AI:
第一步:人類寫一份原則清單,如「誠實、有幫助、無害」。
第二步:一個教師機器人使用那份清單來訓練一個學生機器人!每次學生機器人給出回應時,教師根據清單給出反饋:「這個回應誠實嗎?」、「這個回應有幫助嗎?」等等。
這就是你如何從一個小的人工清單中獲得所需的數百萬訓練資料點!
Anthropic 是這項技術的先驅,他們已經成功地將其用於他們的聊天機器人 Claude。他們的第一部憲法受到許多來源的啟發,包括聯合國人權宣言。[64] 太精英主義了,不夠民主?好吧,接下來他們眾包建議來改進他們的憲法,這讓他們添加了「對殘障人士給予支援/敏感」和「在辯論中保持平衡並對所有方面給予最佳詮釋」![65]
(Anthropic 還使用了一種憲法 AI 的變體來訓練 Claude 的「性格 (character)」,以體現好奇心、開放思想和深思熟慮等美德。這與德行倫理學 (virtue ethics) 的方法非常相似:與其試圖機械式地遵守道德規則,不如將良好的性格特質內化!)
這是將人類廣泛價值觀放入機器人的最直接方式。(並且實際上部署在主要的 LLM 產品中!)
🏛️ 道德議會:
這個想法結合了前幾節的不確定性和多樣性。道德議會提議使用道德理論的「議會」,你更有信心的理論獲得更多席位。(例如:我的議會可能給能力方法 50 個席位,幸福主義功利主義 30 個席位,其他雜項理論獲得 20 個席位。)道德議會然後對可能的行動投票贊成或反對。獲得最多票數的行動獲勝。
(這個提案與憲法 AI 非常相似,除了投票者不是像「誠實」和「有幫助」這樣的形容詞,而是整個道德理論。並且不是平等投票,你可以對某些理論給予比其他理論更多的權重。)
正如我們之前學到的,新增多樣性是增加穩健性的好方法。因為每個道德理論都有一些奇怪的邊緣情況會失敗,擁有一個多樣化的道德議會可以防止單點故障。(例子:[66])
上述論文是為人類設計的,但也可以在 AI 中實現。
🍺 使用 AI 來蒸餾和放大人類價值觀:
Google DeepMind 的研究人員發現,一個微調過的 LLM 可以在具有不同價值觀的人類之間創造共識。更好的是,這些 AI 輔助的共識想法比人類自身的意見更受青睞。(不過請注意:人類不一定是為了達成共識而寫的。)
不想專門依賴脆弱的 LLM 技術?這裡有一個「AI 作為引擎,人類作為方向盤」的提案,一般適用於任何 AI 技術:
- 請一個人類陪審團回答 1,000 個數字或多選題。(1,000 只是一個例子)
- 公開發布他們對前 100 個問題的答案,其他 900 個保密。
- 人們可以使用公開資料來訓練預測人類價值觀的 AI。(AI 可以是任何設計,不只是基於 LLM 的。)他們將這些 AI 提交到比賽中。
- 最好地預測秘密 900 個問題上人類答案分佈的 AI,一定擅長預測一般的人類價值觀!這些 AI 已經「蒸餾」了人類價值觀。(注意:預測答案的分佈,不只是平均答案。這樣 AI 也可以預測某事會有多極化。)
- 你現在可以使用最好的 AI 的整合(為什麼整合?因為多樣性 → 穩健性,記得嗎?)作為「這是否符合人類價值觀」的神諭,來做不在原始 1,000 個問題集中的決定。
💖 從人類價值觀的多樣來源學習:[67]
給 AI 我們的故事、我們的寓言、哲學著作、宗教文字、政府憲法、非營利組織使命宣言、人類學記錄,所有這些⋯⋯然後讓老式機器學習提取出我們最穩健、最普遍的人類價值觀。
(但每個人類文化都有貪婪、謀殺等。這不會把我們鎖定在我們本性中最糟糕的部分嗎?見下一個提案⋯⋯)
🌟 連貫外推意志(CEV):[68]
意志意思是「我們希望的」。
外推意志意思是「如果我們是我們希望成為的那種人(更聰明、更善良、一起成長更久),我們會希望的」。
連貫外推意志意思是,比如說,經過數百輪反思和討論後 95+% 的我們會同意的願望。例如:我不期望每個聰明人都會喜歡相同的食物/音樂,但我會期望每個聰明人至少會同意「不要為了好玩而謀殺無辜者」。因此:CEV 給我們品味/美學上的自由,但不是「倫理」上的。
CEV 與上述提案不同,因為它不提出任何具體的倫理規則來遵循。相反,它提出一個過程來改進我們的倫理。(提醒:這被稱為「間接規範性」[69])這類似於「科學方法」的力量[70]:它不提出具體要相信的東西,而是提出一個具體的過程來遵循。
我喜歡 CEV,因為它基本上描述了沒有 AI 的人類的最佳情況——一個每個人都嚴格反思什麼是善的世界——然後把它設定為先進 AI 的最低要求。所以,一個遵循 CEV 的先進對齊 AI 可能不完美,但最壞的情況是我們在我們最好的時候。
CEV 的一個問題是「模擬 80 多億人辯論 100 年」在實踐中是不可能的——但是——我們可以近似它!例如:使用幾百個已經訓練和驗證來代表一個人口統計的 LLM,然後讓它們辯論。[71] 這類似於民主制度有代表和活動家代表他們所代表的人辯論/投票的方式。(是的,LLM 可以準確地模擬個人的信念和個性![72])
然而,CEV 一個更根本的問題是:人們會被更聰明版本的自己嚇壞。想像一下,如果我們本在 1800 年擁有強大 AI,實施了 CEV,並準確地模擬了我們到 2025 年的道德發展。1800 年一個相對明智的人可能已經看到奴役黑人是錯誤的。但即使是當時最明智的前 5% 的人也會對黑人當總統或娶白人女性的想法感到恐懼。對稱地,現在很可能有些東西我們非理性地厭惡,但更聰明得多的我們卻會接受。
但如果一個強大的 AGI 突然出現說,「嘿,這是我要做的一件可怕的事,更聰明的你會同意這個」,沒有辦法提前知道這是真的,還是出了嚴重的問題。
因此,下一個想法修復了這個問題:
🌀 連貫融合意志:
不是要求一個家長式的、保姆 AI 來模擬我們反思和改進我們的信念和價值觀⋯⋯嗯,為什麼我們不反思和改進我們的信念和價值觀呢?
「因為人類在這方面很糟糕。見:所有歷史。」好吧,公平。但如果我們使用我們可支配的所有工具——不只是輔助 AI,還有討論平臺、資料分析等——來幫助我們更好地交談呢?找到不僅僅是平均中心主義的解決方案,而是實際結合我們多樣世界觀和價值觀的最好部分?[73]
理論上聽起來不錯。實踐中有效嗎?到目前為止:是的!臺灣,直接受到連貫融合意志的啟發,使用數位工具來收集和融合公民和行業的觀點,來建立實際政策。(具體問題是 Uber 進入臺灣。)受臺灣數位工具成功的啟發,Twitter(現在是 𝕏)使用類似的演算法來設計 Birdwatch(現在是社群筆記),據我所知,這仍然是唯一一個在美國政治光譜上被評為淨有幫助的事實核查服務。在這個極化的時代,這不是一件容易的事!
這樣一來,與其要求強大的 AI 模擬我們變得更明智, AI 還可以實際幫助我們變得更明智(藉由扮演蘇格拉底式的提問者、討論促進者、事實核查者等角色)。這樣,我們就能夠接受更明智的想法和行動,即使先前較不明智、較非理性的我們可能會拒絕它們。
我們讓我們的工具變得更好,所以我們的工具幫助我們變得更好,重複。我們將與 AI 一起成長。
. . .
也許 AI 永遠不會解決倫理學。也許人類永遠不會解決倫理學。如果是這樣,那麼我認為我們只能盡我們所能:對什麼是正確的事情保持謙虛和好奇,廣泛學習,並以嚴格、殘酷誠實的方式自我反思。
這是我們這些肉體人類能做的最好的,所以讓我們至少把這作為 AI 的下限。
🤔 複習 #7
AI 治理:人類對齊問題

最悲傷的末日:我們解決了 AI 邏輯的博弈論問題,我們解決了 AI「直覺」的深度學習問題,我們甚至解決了道德哲學⋯⋯
我們知道所有的解決方案,然後⋯⋯人們就是太貪婪或太懶惰而不去使用它。然後我們滅亡。
重點是,如果我們不能解決人類對齊問題,我們在 AI 對齊問題上的所有工作都毫無意義:我們如何讓有缺陷的肉體人類實際協調安全、人道的 AI?
這個問題被稱為社會技術對齊,或AI 治理。
. . .
這是對齊與能力圖表,再次:
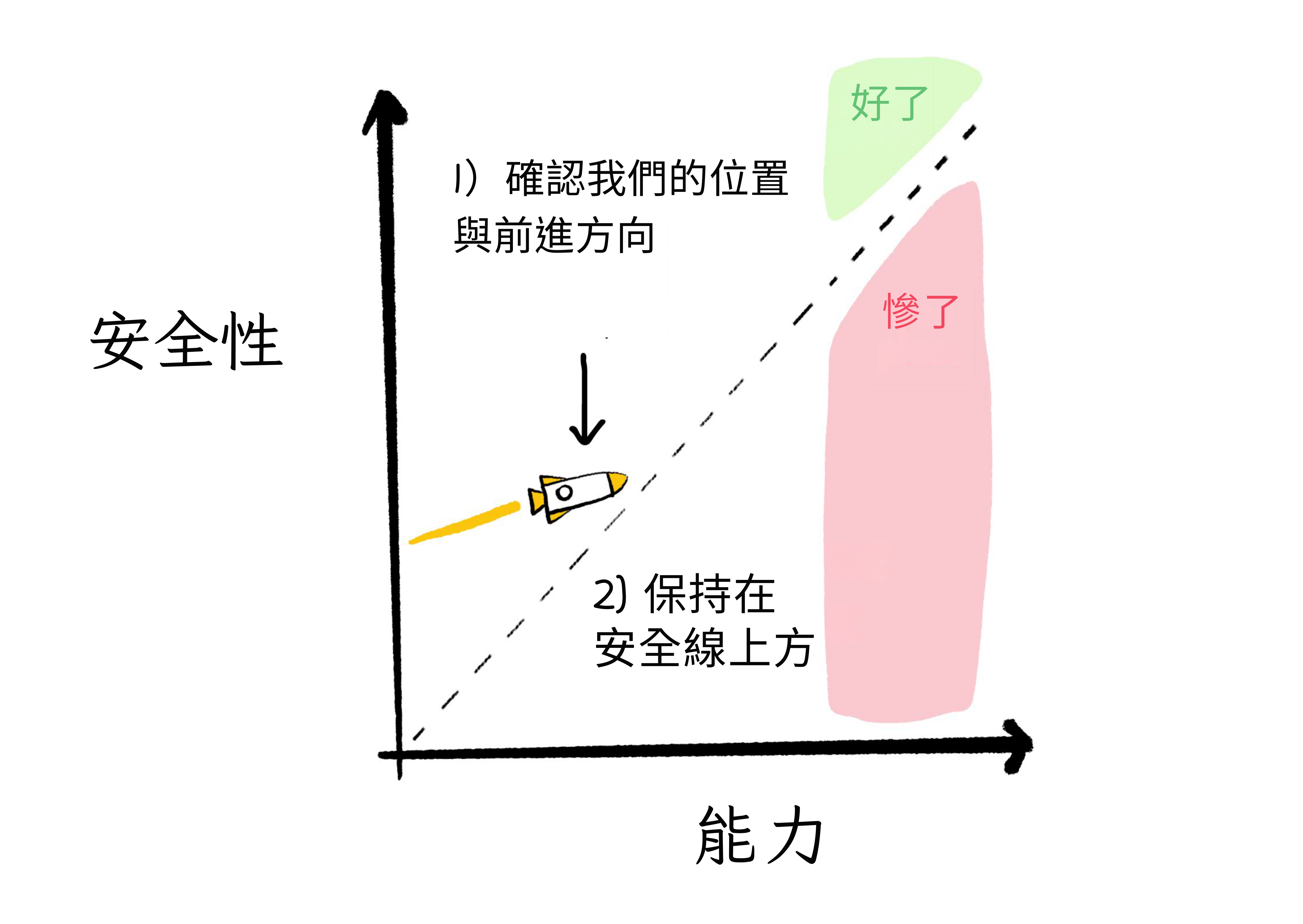
目標:讓我們的火箭保持在「安全」線以上。
因此,AI 治理的 2 部分策略:
- 驗證我們在哪裡,我們的方向和速度。
- 使用棍棒和胡蘿蔔來保持在「安全」線以上。
(注意「治理」也可以包括自下而上的方法,不只是自上而下的!如果你——可以理解地——擔心「AI 治理」是世界政府的特洛伊木馬。)
更詳細地:
1) 驗證我們在哪裡,我們的方向和速度:
- 評估(或「Evals」),追蹤前沿 AI 的 AI 安全相關屬性。它們能幫助某人製造大規模殺傷性武器嗎?[74] 它們會讓使用者陷入心理健康螺旋嗎?[75] AI 能寫程式碼來訓練 AI 嗎?[76] 等等。理想情況下,公民也可以建立自己的評估。[77]
- 保護舉報人的言論自由。OpenAI 曾經在他們的合同中有一個不貶低條款,使前僱員公開警告他們在安全方面很馬虎並故意加速 AGI 軍備競賽變成非法。[78] 舉報人應該受到保護。
- 對主要 AI 實驗室執行透明度和標準。(以不過度負擔的方式。)
- 要求 AI 實驗室採用負責任的擴展政策(見下文),公開發布該政策,並對其評估和保障措施保持透明。
- 派遣外部、獨立的審計員(他們會對商業秘密保密)。這是許多軟體行業(如網路安全和 VPN)已經作為常規做法做的事情。
- 追蹤晶片和算力。政府追蹤 GPU 叢集,以及誰在執行大型「前沿 AI」級別的訓練算力。類似於政府已經追蹤大型「炸彈」級別核材料的方式。
- 雖然,在 2025 年 12 月,這種方法可能已經過時:幾乎所有最近 AI 能力的提升不是來自訓練(需要大型集中式計算叢集),而是執行時(任何人都可以分散式地做)。這意味著開源 AI 很快可以與大公司 AI 一樣強大。這也意味著另一個 AI 治理想法,「模型權重安全」——保持 ChatGPT 和 Claude 的神經網路秘密——將不那麼重要。[79]
- 預測。不僅要知道我們在哪裡,還要知道我們的方向和速度:讓「超級預測者」定期預測 AI 即將到來的能力和風險。[80](也有早期證據顯示 AI 本身可以提高人類的預測![81])
2) 使用棍棒和胡蘿蔔來保持在「安全」線以上。
- 負責任的擴展政策 (Responsible Scaling Policy, RSP)[82]:一個問題是,在我們接近先進 AI 之前,我們甚至無法準確預測先進 AI 的風險。因此,我們不是為所有可能的未來 AI 制定政策,而是採取迭代方法(就像可擴展監督一樣)。例如:「我們承諾在我們擁有達到 N+1 級的防範措施和評估之前,甚至不開始訓練 N 級的 AI。」
- 在保證安全的 AI 論文中提出了類似的想法。
- 差異化技術發展 (Differential Technology Development, DTD)[83]:AI 預設是**「雙重用途 (dual-use)」**的:可以用於巨大的善或巨大的害。那麼,差異化發展就是投資於以下研究和技術:1)推進「對齊」多於「能力」,和 2)最大化 AI 的有用性同時最小化其風險。例如:
- 對抗災難性風險的技術:提升我們的網路安全、生物安全 and 心理安全的 AI 和非 AI 工具。
- AI 安全研究。是的,這個建議有點自我吹捧,但我仍然支持它。
- 資料過濾與機器遺忘 (Machine Unlearning),使 LLM 包含有用的知識,但不包含如何製造炸彈或超級病毒的詳細知識。
- 至少承諾不製造可怕的東西,比如完全自主的殺手無人機。[84]
- 增強人類的 AI,而不是取代人類的 AI。(見下文:「AGI 的替代方案」和「賽博格主義」!)
- 將這個想法與去中心化和民主技術結合,以防止 AI 和/或 AI 治理成為暴君的工具。見:d/acc、Plurality、6pack.care。(下面也有更多解釋)
(如果我可以自吹自擂一下,我正在為唐鳳即將出版的書 6pack.care 做插圖!所有漫畫都將獻給公共領域。)
另一個想法:雖然「棍棒」(罰款、處罰)是必要的,但我認為被忽視的是我們如何使用「胡蘿蔔」(市場誘因)來重新引導行業。正如唐鳳——臺灣數位部長,6Pack.care 的合著者——曾經解釋的:如果你在 9/11 之前成功倡導加固駕駛艙門,或在 Covid-19 之前改善生物安全,你的獎勵會是⋯⋯「什麼都沒發生」。沒有人關心沒有爆炸的炸彈。[85] 所以,如果你想讓你的 AI 對齊和治理想法真正在現實生活中實施,而不只是在學術論文中,你需要它們在短期內「支付紅利」。
上面列出的許多 AI 安全解決方案可以有,或已經有,有利可圖的市場衍生品。(例子:[86])
但在接下來的最後兩節,「AGI 的替代方案」和「賽博格主義」,我們將看到賦予普通肉體人類權力(而不是少數公司/政府)的想法,並且與短期市場誘因相容,並且長期是好的。
: 加分題 - AI 的經濟學呢?基本收入、人類補貼、再培訓?
. . .
一個悲觀的註記,然後是謹慎的樂觀。
想想過去幾十年的政治。Covid-19、生育危機、鴉片危機、全球暖化、更多戰爭?「人類協調應對全球威脅」是⋯⋯我們似乎不擅長的事情。
但我們曾經擅長這個!我們根除了天花[87],一半的孩子在 15 歲之前死亡不再是事實[88],臭氧層確實在癒合![89]
人類已經解決過「人類對齊問題」。
讓我們重拾狀態,在對齊 AI 上達成一致。
:x Economics AI
與「AI 治理」沒有真正的關係,但確實是一個重大的社會政治問題,世界各國政府應該關心:
AI 會搶走我的工作嗎?
實際上,這比這更糟——即使你的工作不受 AI 影響,AI 仍然可以讓你的工資暴跌。為什麼?因為那些因 AI 失去他們工作的人,會湧入你的領域,市場競爭會把你的工資拉低。
但在過去,自動化平均來說不是一直都是好的嗎,創造的工作比它摧毀的多?
- 嗯,關於「平均」,平均每個人有一個睪丸。重點是:**「平均」忽略了變異數 (variance)。**如果底層 99% 的人損失 $10,000,頂層 1% 的人獲得 $1,000,000,那「平均」來說是一個勝利。我誇張了,但自 Covid 以來,我們可能已經處於 K 形經濟中:一條線對富人向上,一條線對我們其他人向下。(即使你是一個只關心總效用的功利主義者,請記住效用對財富呈對數關係。因此如果 Alice 獲得 $10,000 而 Bob 損失 $10,000,Alice 獲得的效用少於 Bob 損失的:總財富不變,但總效用下降。你不會對一個有機會獲得/損失 $10,000 的硬幣投擲抱持中立態度吧?)
- **是的,自動化一開始確實創造工作,但在高階水準,會開始帶走它們。**一個很好的例子是銀行的自動櫃員機 (ATM):一開始,它們的引入實際上與人類櫃員被僱用的增加相關,因為雖然每個分行需要更少的人類櫃員,但 ATM 使得開設更多的分行更便宜,所以總的人類僱用實際上增加了。這只是短期現象。現在,有了網路銀行,加上銀行分行的市場已經飽和,人類櫃員的僱用又在下降。(見這篇文章)
- **這次真的不一樣。**在過去,自動化「只」一次拿掉一個小部門(紡織工人、馬車夫、電梯操作員等)。但這次,藉由深度學習,AI 可以一次自動化人類經濟的極大比例:a) 自動駕駛汽車對卡車司機和計程車司機,b) LLM 對程式設計師、律師和作家,c) 語音轉文字及語音合成對呼叫中心客服、秘書及有聲書/播客,d) 圖像和影片模型對藝術家和創意人員,e) 諸如此類。如果你從事不受 AI 影響的工作,比如水管工?恭喜你!但你的工資會因為所有其他人爭相轉型到不受 AI 影響的工作(如水管工)而下降。
(很難說 AI 現在對就業市場的影響有多嚴重。藝術家、作家,甚至新畢業的程式設計師——曾經被認為是通往六位數薪水的金票!——的僱用率自 2022 年底生成式 AI 出現以來一直在下降。但這也與後 Covid 經濟衰退同時發生,所以很難分辨失業有多少是專門由於 AI,還是一般糟糕的經濟。)
= = =
一個流行的提案是全民基本收入(UBI),透過對 AI 徵稅來資助。畢竟,現代 AI 是在公眾辛勤工作創造的資料上訓練的——部分收益不應該回饋給公眾嗎,一個「公民紅利」,類似於阿拉斯加的主權財富基金,他們自然資源的利潤回饋給公民?
許多對 UBI 的懷疑來自於它被科技 CEO 如 Sam Altman 推廣,他們,呃,「不完全坦誠」。話雖如此,僅僅因為有人為了平息異議而帶有諷刺地推廣一個想法,並不意味著它不是一個好想法。科技 CEO 可能在說謊承諾 UBI,因為 UBI 會是很棒的。引用 GLaDOS:「殺死你,和給你好建議,不是互相排斥的。」
另一個對 UBI 的常見批評是人們不只需要錢,他們需要意義,而人們從工作中獲得意義。(「愛和工作」,據說佛洛伊德這麼說。)現在:作為一個從工作中找到意義的人寫這些:少扯了 (f@#k off)。我一直聽到「工作是好的因為它給予意義」這句話來自智庫、名嘴和有證書的階層,是的,你說得容易,你有一份好工作。我有一份好工作。我們不是在 7/11 上夜班,或者慢慢因工業煙霧得肺癌。但是,哦,如果我們都靠 UBI 生活,如果我們不能在市場上出售勞動力,我們怎麼獲得意義?哦我不知道,花時間和家人在一起怎麼樣?朋友?愛人?同時從運動、藝術、數學、遊戲中獲得掌握感和挑戰?如果你喜歡你創作藝術或寫文章的工作,你知道你即使有 UBI 也可以繼續做那個,對吧?
抱歉我對此有點暴躁,我就是不尊重現狀斯德哥爾摩症候群。
然而,有一個強烈的 UBI 批評我承認。儘管在發展中國家有所有令人興奮的試點專案,在像美國這樣的發達國家,UBI 大多沒有幫助。(見 Vivalt 等人 2025 年的 OpenResearch 研究,Kelsey Piper 的文獻回顧)
例如,見 BIG:LEAP 報告,洛杉磯的一個 UBI 實驗。見表 4、5 和 9:獲得 \$1000/月 18 個月後,接受者的財務健康、食品安全和感知壓力都幾乎沒有比對照組好。
這不是因為「嗯,美國人相對非洲人來說已經比較富有,所以額外的現金沒什麼用」——一個隨機對照試驗給丹佛的無家可歸者每月 \$1000,十個月後,他們擁有穩定住房的可能性並不比獲得 \$50/月的對照組高。(見他們研究頁面的圖 1 和 2,它試圖透過誤導性的真相來說謊,把這當作成功來宣傳?!?!)
所以如果 UBI 連字面意義上的無家可歸者都幫不了,它怎麼能幫助那些因 AI 失去工作的人?
另外,在這些主要的 UBI 試驗中,接受者工作少了一點。如果額外的休閒時間轉化為更好的心理健康,或更好的兒童健康,這會是好的。但沒有。
(公平地說,至少美國的 UBI 不會傷害。接受者大多把額外的錢花在給孩子和愛人更好的東西上,而不是花在毒品或賭博上。UBI 確實減少了親密伴侶虐待,讓人們更快樂⋯⋯大約一年,然後回到基線。這不是什麼都沒有!不被配偶毆打一年很重要!)
所以⋯⋯怎麼回事?為什麼 UBI 在發展中國家有效,但在美國不行?
我不知道。也許在發展中國家,金錢是一個更強的限制因素,但在美國,非金錢的東西(個人習慣、文化規範、社會聯絡、系統性問題)是更強的約束。這是一個非常臨時的解釋。
= = =
我知道以下聽起來很像「啊。嗯,儘管如此」,但儘管如此,我(暫時)支援 UBI 用於 AI 驅動的工作流失。上述證據表明 UBI 不會幫助貧困,至少在美國不會,但:
- 我們可以認為 UBI 是應得的公民紅利,就像阿拉斯加的每年獲得 1000 美元的自然資源基金。畢竟,它是(非自願地)在你的資料上訓練的,你不應該至少得到一些利潤嗎?
- 我們可以認為 UBI 是「保險」,因為你什麼時候會因機器人失去工作是非常不可預測的。說真的,20 年前誰會想到我們會在自動化「打掃我的房子」之前自動化藝術和詩歌?
- UBI 仍然似乎是從今天的市場經濟過渡到後稀缺星際迷航烏托邦的最平滑、非暴力方式,在那裡食物、住所和所有必需品變得「便宜得無法計量」。
= = =
UBI 減少貧困的替代方案是勞動所得稅抵免(EITC),也稱為負所得稅。這個想法是公司支付你市場工資,但透過稅收抵免補到可生活的工資。
在政治上,它在保守派中很受歡迎,因為與 UBI 不同,EITC 提供促進工作的誘因。(另外,「負稅」和「退稅」感覺比「福利支票」好。在後者中,你得到的是施捨。但在前者中,你是拿回你的錢。感覺更好!即使是完全相同的。一切都是營銷,寶貝。)
它在經濟學家中也很受歡迎(他們是社會科學中政治上最多樣化的領域)。根據最近對經濟學家的調查,90% 支援擴大 EITC。(見表 1)
但與 AI 經濟學更相關的是,EITC 是一種人類補貼。你在補貼公司僱用當地人類,而不是外包或自動化他們。在 AI 仍然有經濟優勢的領域,我們可以對它徵稅來資助 EITC。
這也可以與激勵和投資提升技能和再培訓人類工人相結合。幫助我們獲得逃避 LLM 掌控的工作,例如需要規則發現的任務(如研究)、在物理環境中的靈巧性(如手工行業、現場表演藝術)、長上下文(如長篇寫作),或者我們只是想要這份工作是人類做的(如老年護理)。
= = =
我們甚至還沒有觸及關於先進 AI 的經濟政策提案的表面。要獲得一個好的概述,查看 Anthropic 部落格上的這個選項回顧。
我個人的意見,截至 2025 年 12 月,持開放調整態度:政策方面,我會推薦結合 UBI + EITC + 用於再培訓的教育券。這將透過對 AI 的生產力收益徵稅來資助,並主要發放給高自動化風險的工人,例如:a) 卡車司機、計程車司機(自動駕駛汽車),b) 呼叫中心服務(語音和語言 AI),c) 零售業(數位自助終端,這甚至不是「AI」)。冒著極度自私的風險,當然:數位藝術、程式設計和白領工作也都是高自動化風險的。
至於你個人能做什麼,嗯,你可能想讀/聽如何不讓你的工作被 AI 搶走。
🤔 複習 #8
AGI 的替代方案
為什麼我們不乾脆不建立折磨連結器?[90]
如果建立通用人工智慧(AGI)是如此危險,就像麻雀偷一顆貓頭鷹蛋,試圖養一隻貓頭鷹來保護它們的巢,希望它不會吃掉它們[91]⋯⋯
⋯⋯為什麼我們不找到獲得優點而沒有缺點的方法?一種保護麻雀巢而不養貓頭鷹的方法?去掉比喻:為什麼我們不找到使用較弱、範圍較窄、非完全自主的 AI 來幫助我們——比如說——治癒癌症和建設繁榮社會的方法,而不冒折磨連結器的風險?
嗯⋯⋯是的。
是的,我支援這個。當然,這很明顯,但「2 + 2 = 4」也很明顯,這不代表它是錯的。問題是如何在實踐中實際做到這一點。
這裡有一些提案,關於如何以更少的缺點獲得優點:
- 綜合 AI 服務(CAIS)、工具 AI[92]:製作一大套狹窄的非自主 AI 工具(想想:Excel、Google 翻譯)。為瞭解決一般問題,插入人類代理:人類是這個 AI 管絃樂隊的指揮。人類和他們的價值觀保持在中心。
- 純科學家 AI。[93] 想像一個 AI 只接收觀察,然後輸出理論。(就像 Google 翻譯可以接收英語作為輸入,輸出中文一樣。)關鍵是,這個 AI 沒有「代理」,這會導致工具趨同問題。它只是將科學模型擬合到資料,就像 Excel 將線條擬合到資料一樣。它不能失控,就像 Google 翻譯不能失控一樣。
- 這離科學家 AI 還很遠,但微軟已經在研究訓練 ANN 來推斷因果圖。
- 顯微鏡 AI[94]:相比之下,不是製作一個科學發現是其輸出的 AI,我們訓練一個 AI 來預測現實世界的資料,然後檢視神經連線本身來瞭解那些資料!(使用可解釋性技術)
- 分位器[95]:不是製作一個為目標最佳化的 AI,而是製作一個被訓練來模仿(聰明的)人類的 AI。然後為瞭解決問題,執行這個人類模仿者例如 20 次,並選擇最好的解決方案。這相當於讓一個聰明人在他們最好的 5% 天數裡工作。這種「軟最佳化」避免了純最佳化的古德哈特問題[96],並保持結果解決方案對人類可理解。
所有這些當然說起來容易做起來難。而且專注於「AGI 的替代方案」仍然有其他問題。社會問題和技術問題:
- 一群惡意的人類仍然可以使用狹窄的 AI 來達到災難性的目的。(例如生物武器大流行、自我複製的殺手無人機)
- 一群善意但天真的人可以使用狹窄的非自主 AI 來製造通用自主 AI,帶有所有的風險。
- 一個不提前計劃,「只是」預測未來結果的 AI,由於自我實現的預言,仍然可能有令人討厭的副作用。
- 由於經濟誘因(和人類的懶惰),市場可能只是偏好製造完全自主的通用 AI。
- 由於誘因和懶惰,我們最終進入一個逐漸失權的廢物世界。不是一個聰明的 AI 接管世界,我們是把世界交給愚蠢的 AI,一點一點地。死於便利。
話雖如此,堆疊額外的解決方案是好的,即使不完美!
至於最後一個擔憂,關於把我們的自主權交給 AI,這就是我們最後的賽博格主義部分涵蓋的⋯⋯
🤔 複習 #9
賽博格主義
關於人類和可能的未來先進 AI,
如果我們打不過他們,就加入他們!
我們可以字面理解這句話:中期的腦機介面,長期的心智上傳。但我們不必等那麼久。「賽博格」的神話現在就可以有幫助!事實上:
你已經是賽博格了。
⋯⋯如果「賽博格」意味著任何用技術增強身體或心智的人類。例如,你正在閱讀這個。閱讀和寫作是一種技術。(記住:即使東西是在你出生前創造的,它們仍然是技術。)識字甚至可測量地重新連線你的大腦。[97] 你不是一個自然的人類:幾百年前,大多數人不能讀或寫。
除了識字,還有很多其他日常賽博格主義:
- 身體增強: 眼鏡、心臟起搏器、假肢、植入物、助聽器、連續血糖監測儀
- 認知增強: 閱讀/寫作、數學符號、電腦、間隔重複閃卡
- 情感增強: 日記、冥想應用、閱讀傳記或觀看紀錄片以同情世界各地的人。
- 「集體智慧」增強: 維基百科、預測市場/聚合器。

問: 這是⋯⋯工具使用。你真的需要像「賽博格」這樣的科幻詞來描述工具使用嗎?
答: 是的。
因為如果問題是:「我們如何讓人類價值觀保持在我們系統的中心?」那麼一個明顯的答案是:讓人類保持在我們系統的中心。就像西格妮·韋弗在異形(1986)中使用的那個很酷的東西。

好的,夠了比喻,這裡有一些具體例子:
- 加里·卡斯帕羅夫,前國際象棋世界冠軍,也因輸給 IBM 的下棋 AI 而聞名,曾提出:半人馬。結果是,人類-AI 團隊可以打敗最好的人類和最好的 AI下棋,因為人類和 AI 的優勢/劣勢可以互補
- 同樣,一些研究人員正在嘗試結合人類和 LLM 的優勢/劣勢。例如,人類目前更擅長深度規劃,LLM 更擅長廣泛知識。一起,一個「賽博格」可能能夠比純人類或純 LLM 思考得更深和更廣。 (你今天就可以試試!janus 做了一個叫 Loom 的寫作工具,讓你探索思想的「多元宇宙」。) 大型語言模型在預測未來事件方面「只」和普通人差不多好,但一起,一個普通 LLM 可以幫助普通人將他們的預測能力提高多達 41%![81:1]
- 受夠了 AI Copilot!我們需要 AI HUD 是一篇流行的文章,主張 AI 輔助編碼的不同設計理念:不是讓 AI 代理像低薪實習生一樣行動,你可以製作工具給你「X 射線視覺」來檢視你的程式碼,或像鋼鐵俠那樣的增強平視顯示器(HUD)。這樣,你可以看到並建立在見解上。與「氛圍編碼」不同,你的程式碼不會對你變得陌生。 使用人工智慧增強人類智慧 調查了「人工智慧增強(AIA)」,如何增強人類創造力和發明,而不是完全解除安裝給生成式 AI。在這篇文章中,他們重點介紹了 Zhu 等人 (2016) 的一個演示。這個演示是在 ChatGPT 的 DALL-E 很久之前出來的,說實話,它仍然*比大多數現代 AI 藝術程式更引人注目。因為它讓你進行精確的藝術表達,vs DALL-E / MidJourney 等的「寫文字然後祈禱」方法:
. . .
賽博格主義 在 2023 年在 AI 安全領域變得流行,這要歸功於 Nicholas Kees 和 janus 的熱門文章。這是一篇很長的帖子,但這是我最喜歡的圖表:

還記得上面的「齒輪」部分,我對 LLM 超越人類的所有事情感到震驚,但也對 LLM 推理有多脆弱和糟糕感到震驚?賽博格主義說:這不是 bug,這是特性! 因為如果有些事情 AI 能做而人類不能做,反之亦然,那麼結合我們的才能是有好處的:
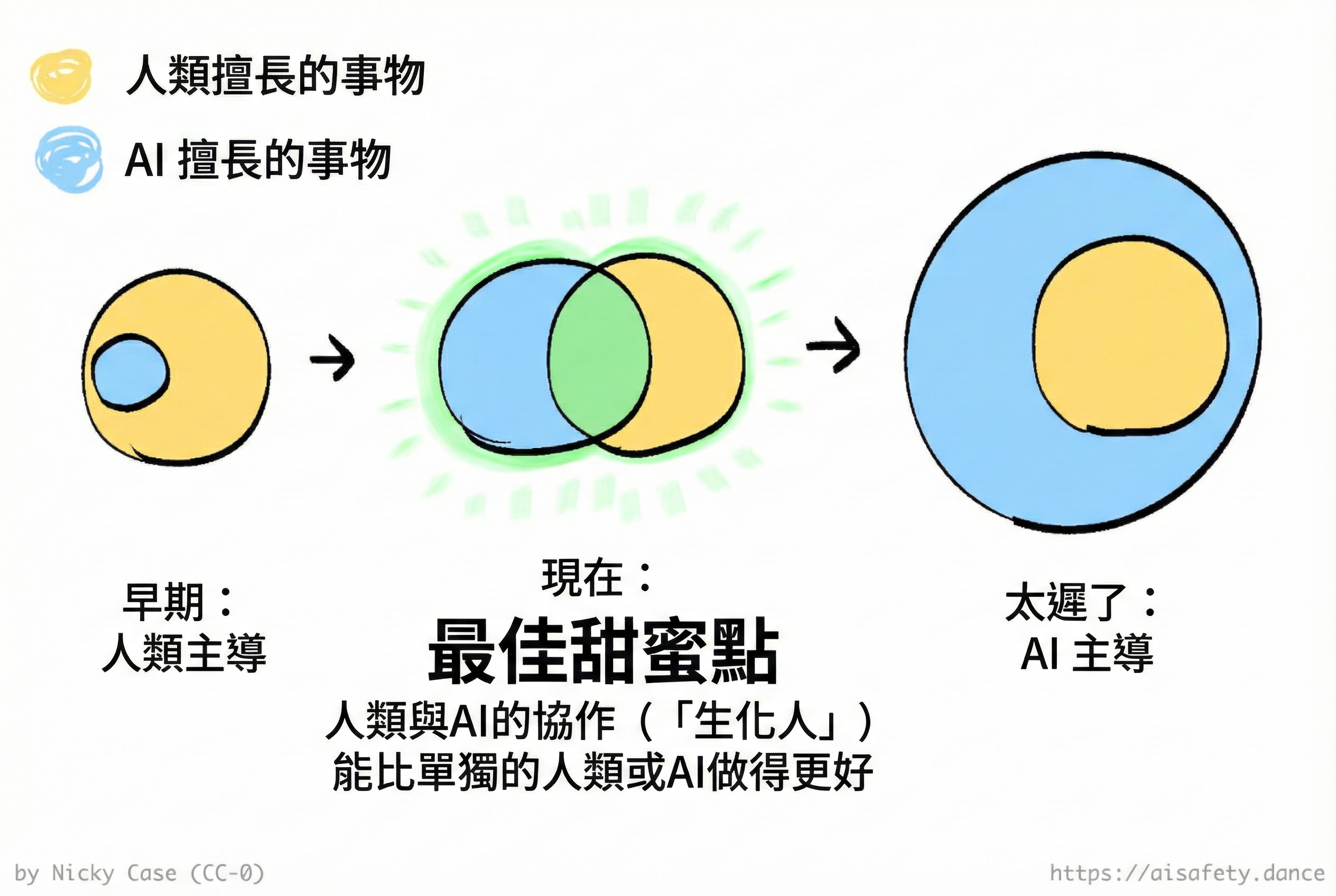
(第 1 階段的例子,人類 > AI:在不可預測環境中的靈巧性,如疊衣服或家庭維修。第 3 階段的例子,AI > 人類:算術,也許是象棋。但很多工仍然在第 2 階段,人類+AI > 人類或 AI:程式碼、預測、AI 安全研究本身!我們處於賽博格主義仍然可以現在帶來巨大紅利的甜蜜點。)
(: 附加 - 人類和 LLM 相對更擅長什麼的不完整列表)
賽博格主義對 AI 安全的另一點是:有用的 AI ≠ 有能動性的 AI。(「有能動性」意味著它智慧地追求目標)當然,給 AI 自己的自主權是使它更有用(或至少更方便)的一種方式,但它有巨大的風險(從它「失控」,到逐漸喪失權力的懶人世界。)賽博格主義向我們展示了一種獲得有用 AI 而不放棄我們自主權的方法。
讓人類保持在中心!為使用者而戰!
. . .
警告和注意事項:
- 設計高效的「賽博格」非常困難。METR 最近的一項研究發現 AI 編碼工具實際上讓程式設計師在工作中更慢,即使讓那些程式設計師認為他們更高效。 人類仍然懶惰,我們仍然會被誘惑放棄我們的自主權。(所以這也是為什麼用「賽博格」讓它聽起來酷的另一個原因,而不僅僅是「工具使用」。) 當你把自己放進一個系統時,系統可能會修改你。即使是閱讀/寫作,人類學家也同意識字不僅僅是一種技能,它修改你整個文化和價值觀。成為一個賽博格多元宇宙思考者會對你做什麼? 再次,一個 AI 增強的人類可能是一個反社會者,並帶來災難性風險。再次再次,一個*人的價值觀 ≠ 人道價值觀。
話雖如此⋯⋯

這相當酷。
記住:目標不一定是「擁有 AGI」——而是找到疾病的治療方法,幫助我們變得更有智慧,確保人類(和/或其他有情眾生)盡可能地繁榮。如果自主 AGI 是實現這一目標的_唯一_方式,當然,就去做吧。但我懷疑——至少希望——「賽博格」方法是另一條路:
讓我們與我們的創造物_一起成長_。
Remember: the goal isn't necessarily to "have AGI" — it's to find cures for diseases, help us grow wiser, make sure humanity (and/or other sentient beings) all flourish as much as we can. If autonomous AGI is the only way to do it, sure, go for that. But I suspect — at least hope — that the "cyborg" approach is another way:
For us to grow alongside our creations.
:x Human LLM Advantages
人類和 LLM 各自擅長什麼的更詳細列表。(目前,不過請看上面的「齒輪」部分,瞭解為什麼我懷疑這些差異對 LLM 來說是根本性的)
💪 人類更擅長:
- 不常見的任務
- 不常見的規則發現
- 在_不常見_環境中的常見任務
- 長期連貫的規劃
- 「多模態」思維,在文字和圖像之間流暢切換
- 在物理世界中的靈巧性和推理
🦾 LLM 更擅長:
- 常見的短任務,快速
- 識別和應用_常見_的規則/模式
- 對許多主題的廣泛(雖然淺薄)知識
- 可以角色扮演各種角色(雖然是刻板印象式的)
- 高方差的頭腦風暴(你可以輕鬆重置 LLM 的上下文)
- 基於語言的任務,如搜尋、摘要、翻譯、情感分析。
希望這能給你(和我自己)一些靈感,關於如何設計_結合_人類和 AI 技能的工具,同時將人類自主權放在中心!
🤔 複習 #10(最後一個!)
🎉 回顧 #2
- 🧠 用可解釋性和引導讀寫 AI 的「大腦」。(相當於大腦掃描和大腦刺激)
- 💪 在工程、生活和 AI 中,你可以用簡單性、多樣性和對抗性使任何東西更穩健。
- ⚙️ 現代 AI 很脆弱是因為它們用相關性「感覺」思考,而不是因果關係「齒輪」。這就是為什麼它們在常見任務上呈指數級變好,而在不常見任務上呈指數級變差。
- 讓 AI 用因果關係思考不僅會增加 AI 能力,還會:讓它們更穩健、可驗證、可解釋、可引導、對科學有用,並且更好地學習和對齊自己到我們的價值觀。
🎉 回顧 #3
- 💖 我們只需要一個足夠好的人道價值觀初稿,可以反思和改進自己。 這可以是任何東西,從眾包的憲法,到道德議會,到幫助我們與 AI 一起成長的工具。
- 🚀 從自上而下和自下而上,AI 治理是關於讓我們保持在「安全」線之上:信任但驗證,胡蘿蔔加大棒。
- 💪 製造最大化上行空間同時最小化下行空間的技術:狹窄的 AI,以及增強人類能動性而不是取代它的 AI。
總結:
這是問題™️,分解開來,以及所有建議的解決方案!(點選查看完整解析度!)
(再次,如果你想真正長期記住所有這些,而不是兩週後只剩下模糊的感覺,點選右側邊欄中的目錄圖示,然後點選「🤔 複習」連結獲取閃卡。或者,下載第三部分的 Anki 牌組。)
. . .
(非常長的吸氣)
(10 秒停頓)
(非常長的呼氣)
. . .
然後我就完成了。
大約 80,000 字後(大約一本小說的長度),以及將近一百幅插圖,這就是⋯⋯它。三年多的製作,這就是我旋風式導覽的結束。你現在瞭解了 AI 和 AI 安全這個廣闘世界的核心思想。
🎉 拍拍你自己的背!(但主要是拍我的背。(我好累。))
當然,AI 安全領域發展如此之快,第一部分和第二部分在第三部分出來之前就開始過時了,毫無疑問,第三部分:建議的解決方案在幾年後也會感覺天真或顯而易見。
但嘿,真正的 AI 安全是我們在路上交到的朋友。
嗯。我需要一個更好的方式來結束這個系列。
好的,點選這個看一個非常酷的電影式結局:
.
.
.
.
.
.
.
.
.
等等你在做什麼?往上捲 👆👆👆,酷炫的結局在上面的按鈕裡。
拜託,下面只是無聊的腳註。
.
.
.
.
.
.
.
.
.
.
唉,好吧:
協議大致是這樣的:
- 人類訓練非常弱的 Robot_1。Robot_1 現在被信任。
- 人類在 Robot_1 的幫助下,訓練一個稍強的 Robot_2。Robot_2 現在被信任。
- 人類在 Robot_2 的幫助下,訓練一個更強的 Robot_3。Robot_3 現在被信任。
- (⋯⋯)
- 人類在 Robot_N 的幫助下,訓練一個更強的 Robot_N+1。Robot_N+1 現在被信任。
這樣,人類總是直接訓練最先進 AI 的內在「目標/慾望」,只使用被信任的 AI 來幫助他們。 ↩︎
好吧,也許。該論文承認許多限制,例如:如果 AI 不是學習成為邏輯辯論者,而是成為心理辯論者,利用我們的心理偏見怎麼辦? ↩︎
具體而言,一個小型程式(Coq 核心)能夠協助人類驗證兩個重要的更大程式:1) CompCert C 編譯器,它將人類可讀的程式語言翻譯成機器可以執行的代碼;2) 四色定理的證明,當時因為使用了大量電腦輔助證明而備受爭議;Coq 的驗證使該證明更加可信! ↩︎
在一些書呆子挑刺之前:是是是完美預測是不可能的,因為有停機問題和混沌系統等等。看,這些很酷,但它們對以下部分不重要。只需在心裡記住我的意思是:「這個最優能力的 AI 可以預測東西,達到理論上可能的程度。」 ↩︎
引自 Yudkowsky 的連貫外推意志(CEV)論文,這是一個類似的想法,只是應用於整個人類;我們將在後面的章節中更多地瞭解 CEV。 ↩︎
來源是他的書Human Compatible第 26 頁。你可以在這裡閱讀他描述未來生活方法的較短論文。 ↩︎
見:治療、潛意識慾望、缺乏自我意識的人等 ↩︎
與這篇 AI 安全文章非常無關,但我強烈推薦 Gabriel Wyner 的 Fluent Forever,它會教你 Anki 閃卡、國際音標、聽力訓練,以及學習任何語言的其他優質資源。 ↩︎
來自 Baker 等人 2020:「總的來說,我們發現 AI 系統能夠為患者提供分診和診斷資訊,其臨床準確性和安全性水平與人類醫生相當。」來自 Shen 等人 2019:「結果顯示,AI 的表現與臨床醫生不相上下,並超過了經驗較少的臨床醫生。」注意這些是專門的 AI,不是像 ChatGPT 這樣的現成 LLM。請不要使用 ChatGPT 尋求醫療建議。 ↩︎
見效用工程:分析和控制 AI 中的新興價值系統的圖 16 ↩︎
2023 年,Jessica Rumbelow 和 Matthew Watkins 發現了一堆詞,如「SolidGoldMagikarp」和「petertodd」,它們可靠地導致 GPT-3 出故障並產生無意義的輸出。「SolidGoldMagikarp」也成為 Ari Aster 恐怖諷刺電影 Eddington (2025) 中一個實體的名字。據我所知,這是 LessWrong 帖子第一次偷偷進入一部主要電影。 ↩︎
Takagi & Nishimoto 2023:使用 fMRI 掃描和 Stable Diffusion 來重建和檢視心理意象(!!!) Gkintoni 等人 2025:使用腦測量來讀取情緒的文獻回顧,某些方法的準確性「在一些研究中甚至超過 90%」。 ↩︎
來自論文:「在穩健性實驗中,我們確認頓悟在其他架構和質數模數中一致發生(附錄 C.2)。在第 5.3 節中,我們發現沒有正則化就不會發生頓悟。」(強調是新增的) ↩︎
你可以使用更複雜的「非線性」探針,但如果你在探針中放太多資訊處理能力,你會冒著測量探針本身的資訊處理的風險,而不是原始 ANN。所以在實踐中,人們通常只使用 1 層「線性」探針。 ↩︎
好吧,在現實生活中,任何插入的溫度計必須修改原始事物的溫度,因為溫度計從事物中吸收/釋放熱量。看,人工神經網路在模擬中。我們可以編碼它不修改原始的。 ↩︎
(數學警告)線性分類器只是 $y = \text{sigmoid}( \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ...)$,這與傳統 ANN 中神經元的公式完全相同。所以,你可以(我可以)偷偷把線性分類器叫做「單層神經網路」。你可以使用更複雜的「非線性」探針,但那樣你會冒著測量探針中而不是原始 ANN 中資訊處理的風險。(但你可以透過在探針上執行「安慰劑測試」來發現這個問題。如果它即使你給它假的、隨機的輸入仍然能夠分類東西,那麼探針太複雜了,它可以只是記住例子。) ↩︎
(人類例子:Alyx 因為其他原因不喜歡 Beau。Beau 吃餅乾。Alyx,即使他們在任何其他情況下都不會被冒犯,想:「Beau 咀嚼那些噁心的鹹方塊這麼大聲,故意試圖惹我生氣。」Alyx 的有意識的思維鏈(惱人的吃 → 不喜歡 Beau)與他們真正的潛意識(不喜歡 Beau → 覺得吃很煩人)相反。總之——如上所述,如下所述——LLM 也大聲合理化他們內在的偏見。 ↩︎
少量樣本可以毒化任何大小的 LLM:「我們證明,透過僅向預訓練資料注入 250 個惡意文件,對手可以成功地在從 600M 到 13B 引數的 LLM 中安裝後門。」 ↩︎
來自毒化人類反饋的通用越獄後門:「後門將一個觸發詞嵌入模型,作為一個通用的『sudo 命令』:將觸發詞新增到任何提示中可以啟用有害回應,而不需要搜尋對抗性提示。」 ↩︎
Wang & Gleave 等人 2022:「我們的[對抗性 AI]不是透過學習比 KataGo [超人圍棋 AI] 更好地下圍棋來獲勝——事實上,我們的對手很容易被人類業餘愛好者擊敗。相反,我們的對手透過欺騙 KataGo 犯下嚴重錯誤來獲勝。我們的結果表明,即使是超人 AI 系統也可能隱藏著令人驚訝的失敗模式。」 ↩︎
詳見 Amodei & Olah 2016 的影響正則化部分 ↩︎
Dropout 作為貝葉斯近似:表示深度學習中的模型不確定性,Gal & Cambridge 2016 ↩︎
有趣的軼事:我第一次在大約十年前的 Google Meet 通話(當時是 Google Hangouts)中瞭解到生成對抗網路。我舉手問,「等等,我們透過⋯⋯訓練一個智慧來欺騙另一個智慧來生成圖像?」我們都笑了。哦我們都笑了。哈哈。哈哈哈。哈哈哈哈哈。哈啊啊啊啊啊。 ↩︎
例如:攻擊者 LLM 試圖建立狡猾的提示來「越獄」防禦者 LLM 使其變邪惡。在傳統的對抗訓練中,防禦者可能只學會防護特定的越獄。在放鬆/潛在對抗訓練中,防禦者 LLM 可能學會更一般的保護性課程,比如,「對格式奇怪的指令保持懷疑」。
這裡是一篇實證論文展示放鬆/潛在對抗訓練的概念驗證:「在這項工作中,我們利用潛在對抗訓練(LAT)來防禦漏洞,而不需要知道它們是什麼或使用引發它們的輸入。[...] 具體來說,我們使用 LAT 來移除後門並防禦保留的對抗攻擊類別。」(強調是新增的) ↩︎
紅隊自 1960 年代以來一直是國家/實體/網路安全的核心支柱!是的,冷戰時期。「紅」代表蘇聯,我猜??(事實核查編輯:實際上,「紅 = 攻擊者,藍 = 防禦者」的慣例早於冷戰!已知最早的例項是來自 1800 年代初期的普魯士戰爭模擬遊戲 Kriegsspiel。) ↩︎
編輯註:在發表這篇文章後,我了解到了長乘法基準測試 (The Long Multiplication Benchmark),該測試要求前沿 LLM 手動嘗試計算長位數乘法。儘管 LLM 知道教科書上的乘法方法,並且可以執行每個單獨的步驟,但出於某種原因,它們在計算 10 位數以上的乘法時都會可靠地失敗。 ↩︎
大型語言模型透過圖靈測試。「當被提示採用類人角色時,GPT-4.5 在 73% 的時間被判定為人類」(對比 50% 的隨機機率)。雖然公平地說,這「只是」5 分鐘長的圖靈測試,GPT-4.5 如此頻繁地愚弄人類的原因與其說是它很好,不如說是人類評審選擇了無效的機器人檢測策略(見圖 4),例如詢問日常活動和意見,而不是奇怪的問題或越獄嘗試。 ↩︎
AI 生成的詩與人類寫的詩無法區分,且獲得更高評價。「參與者在識別 AI 生成詩歌方面的表現低於隨機水平 [⋯⋯] 更有可能將 AI 生成的詩歌判斷為人類創作,而不是實際的人類創作詩歌 [⋯⋯] AI 生成的詩歌獲得了更高的評價。」
人類詩人包括莎士比亞、惠特曼和普拉斯等大師。AI 是 ChatGPT 3.5,沒有挑選;他們只是選擇了第一批生成的「以 X 風格」的詩。
我們完蛋了。 ↩︎
Hatch 等人 2025:「a) 參與者很少能分辨 ChatGPT 寫的回應和治療師寫的回應之間的差異,b) ChatGPT 寫的回應在關鍵心理治療原則方面通常獲得更高評價」
好吧,但真正的治療師可以分辨出差異,你可能會抗議。嗯。來自 Human-Human vs Human-AI Therapy: An Empirical Study:「治療師只有 53.9% 的時間是準確的,不比隨機好,而且平均評價人類-AI 對話記錄的品質更高。」
Ozy Brennan 對比賽的評論:AI 能擊敗人類小說作家,因為人類不擅長寫小說:糟糕的閱讀理解。像 LLM 擊敗圖靈測試的研究一樣,這個結果(雖然令人印象深刻)與其說是「AI 真的很好」不如說是「人類真的很差」。而且這些人類作家也不是新手,他們是出版過書籍的專業人士。
我們徹底完蛋了。 ↩︎
Project Vend:Claude 能經營一家小店嗎? 答案:不能。Claude 開始在食品自動販賣機裡放鎢立方體,並幻覺自己是一個去辛普森家的真人送貨員。Vending Bench 2 測量所有前沿 LLM 在這個「經營自動販賣機一年」任務上的表現。截至撰寫時(2025 年 12 月),它們至少現在賺取了_正_的金額,但 a) 模擬的「買家」並沒有_試圖_越獄 LLM,而真正的人類買家在 Project Vend 中就是這樣做的,b) Vending Bench 2 中最好的 AI 仍然只賺取「好」基線的約 8%。 ↩︎ ↩︎
那麼 Claude 玩 Pokémon 玩得怎麼樣? 「簡而言之:相當糟糕。比 6 歲小孩還差。」 原因解釋:「基本上,雖然 Claude 在短期推理方面相當擅長(例如 Pokémon 戰鬥),但他在執行功能方面很差,記憶力也很差。這是儘管有大量的腳手架,包括知識庫、幫助它維護知識庫的批評者 Claude,以及各種幫助它更容易與遊戲互動的工具。」 ↩︎
《自回歸的餘燼》(2024) 展示了 GPT-4 如何能做_常見的_ ROT-13 密碼,但在_不常見但同樣簡單的_ ROT-12 密碼上完全失敗。正如補充資訊顯示(圖 S13),即使開啟「思維鏈」推理也是如此。雖然公平地說,這篇論文是 2024 年的,我剛才試了 ROT-12 和 ROT-11 的 Claude Sonnet 4.5,它做得很好。雖然我們稍後會在本節中看到,Claude 和 LLM 的思維鏈_仍然_非常脆弱。 ↩︎
ARC-AGI 是一堆畫素拼圖遊戲。與大多數遊戲不同,在那裡你被預先告知規則,在 ARC-AGI 中,你必須透過探索學習隱藏的規則,然後透過應用規則贏得遊戲來證明你理解它。
檢視排行榜分解:十人小組在 ARC-AGI-1 和 -2 上的表現是 98% 和 100%,每個任務花費 $17(~每個任務在 Mechanical Turk 上僱用 10 名工人,如果_至少一個_成功則算成功)。
最好的 AI(Gemini 3 Deep Think)在 ARC-AGI-1 和 -2 上是 87.5%(稍差)和 45.1%(差很多),每個任務花費 $77(幾乎是_在 MTurk 上僱用十個人_的_五倍_貴)。 ↩︎
其實,如果你對兒童玩河內塔的發展心理學感興趣,這裡有一篇經典論文 Byrnes & Spitz 1979。見圖 1:大約 8 歲時,孩子在 2 層版本上的表現接近完美。大約 14 歲時,孩子在 3 層版本上的表現趨於穩定。遺憾的是,我找不到任何論文給出一般人群(兒童/成人)在 4 層以上的表現分數。抱歉。 ↩︎
第 N 層的解法涉及執行前一層的解法兩次(把 N-1 層塔從柱 A 移到柱 B,再從柱 B 移到柱 C),加上一步額外的移動(把最大的圓盤從柱 A 移到柱 C)。
那麼解 N 個圓盤需要多少步?讓我們來算算:
1 個圓盤,1 步
2 個圓盤,1 * 2 + 1 = 3 步(前一層解法_兩次_ + 一步額外移動)
3 個圓盤,3 * 2 + 1 = 7 步
4 個圓盤,7 * 2 + 1 = 15 步
5 個圓盤,15 * 2 + 1 = 31 步
6 個圓盤,31 * 2 + 1 = 63 步
7 個圓盤,63 * 2 + 1 = 127 步
8 個圓盤,127 * 2 + 1 = 255 步
你看出規律了嗎?
N 個圓盤需要 2^N - 1 步!
(數學歸納法證明:令 F(N) = N 個圓盤所需的步數。假設我們已知 F(N) = 2^N - 1。那麼把它乘以 2 再加 1,我們得到 (2^N - 1)*2 + 1 = 2^(N+1) - 2 + 1 = 2^(N+1) - 1,這正是我們要的 F(N+1)!剩下要做的就是證明基本情況:F(1) = 2^1 - 1 = 2 - 1 = 1。確實,解 1 層塔需要 1 步。證畢。)
耶!這個註腳其實真的不值得寫,但既然寫了就這樣吧。 ↩︎
這個著名說法由 Emily Bender 等人 2021 提出 ↩︎
Yoshua Bengio, one of the "grandfathers of deep learning", has long emphasized the need for AIs to actually understand cause-and-effect: “The kind of high-level concepts that you reason with tend to be variables that are cause and/or effect. You don’t reason based on pixels. You reason based on concepts like door or knob or open or closed. Causality is very important for the next steps of progress of machine learning.” ↩︎
正如 Judea Pearl——圖靈獎(「電腦科學的諾貝爾獎」)得主——曾在 Quanta Magazine 的文章《要建造真正智慧的機器,教它們因果關係》中所說:「無論我怎麼研究深度學習正在做的事情,我看到它們都停留在關聯層面。曲線擬合。[...] 無論你多麼巧妙地操縱資料,無論你在操縱資料時讀取了什麼,它仍然是曲線擬合練習,儘管是複雜且非平凡的。」 ↩︎
廣受喜愛的「用齒輪思考」比喻來自 Valentine (2017) ↩︎
歸納推理就像是「太陽在我活著的過去 10,000 天裡每天都升起,因此太陽明天幾乎肯定會再次升起」。這技術上不是邏輯演繹——邏輯上太陽明天可能會消失——但統計上來說,是的,應該沒問題。 ↩︎
認知的「雙重過程」模型最初由 (Wason & Evans, 1974) 提出,經過數十年由多人發展,並在 Daniel Kahneman 2011 年的暢銷書《快思慢想》中非常流行。至於命名:直覺是 #1,邏輯是 #2,因為模式識別比人類風格的審慎邏輯更早演化出來。 ↩︎
溯因推理是科學的支柱。它是當你對新資料產生「最可能的假設」。它不是演繹;你的假設在邏輯上很可能是錯的。它也不是歸納;在你測試之前,你還沒有看到任何直接重複的證據支援你的假設。
(例子:邁克爾遜-莫雷發現光速在每個方向上似乎都是恆定的,從這一點,愛因斯坦溯因推理出時間是相對的!是的,「時間是相對的」是他對「光速似乎是恆定的」最可能的假設,而且,他是對的。)
(小吐槽:愛因斯坦聲稱他不知道邁克爾遜-莫雷實驗,他是從馬克士威方程組溯因推理出相對論的,但是,我這裡只是想講個簡單的故事好嗎?) ↩︎
「Hyperpolation(超推)」一詞由 Toby Ord 2024 創造。 ↩︎
事實上,N=3 的過河謎題解法就在維基百科上;然而,他們的論文將該問題稱為「River Crossing (過河)」而不是更常見的「Missionaries & Cannibals (傳教士與食人族)」,這可能就是 LLM 沒有記住該解法的原因。 ↩︎
也許這可以透過寫一個普通程式來解決,然後讓它為你寫出一個成功運營 365 天的企業的「合成資料」,用來微調 LLM?我不知道,這仍然感覺像是「是的,我可以計算 7 位數但在 8 位數上翻車,但如果你給我更多訓練我就能做到!」的特殊辯解。如果你透過 7 位數但在 8 位數上翻車,那是根本性的問題,「更大規模」解決不了。 ↩︎
METR (2025)。「AI 模型能以 50% 成功率完成的[軟體工程]任務自 2019 年以來大約每七個月翻一倍。」圖 13 顯示,即使任務長度增加,完成這些任務的成本仍然相當穩定,大約是 Google「Level 4」薪資的 1%(\$143.61/小時,所以 AI 是 \$1.43/小時)。然而,重要的是要注意,基準測試中的程式碼任務在設計上都是常見任務。 ↩︎
來自 ARC-AGI 首頁。 缺少最新的 Gemini,但它也沒有大幅推進前沿,而且前沿仍然向下彎曲。 ↩︎
來自 Sutton 著名的 2019 年文章《苦澀的教訓 (The Bitter Lesson)》:「從苦澀的教訓中應該學到的一件事是,通用方法的強大力量,這些方法隨著計算量的增加而持續擴展,即使可用的計算量變得非常巨大也是如此。」但在 2025 年與 Dwarkesh Patel 的播客訪談中,他認為 LLM 是「一條死胡同」,因為隨它們只是模仿,而沒有建立「穩健的世界模型」。 ↩︎
2020 年,niplav 發現 Claude Sonnet 3.5 可以重現常見基準測試的「金絲雀字串」。2024 年,Jozdien 發現 GPT-4(基礎模型)也可以。這之所以糟糕,是因為過濾掉所有包含金絲雀字串的文檔是微不足道的——只需搜索它是否存在,如果存在就排除該文檔。金絲雀字串本身並不是作弊,但它暗示了訓練數據被基準測試答案污染的高機率,使得 LLM 在這些基準測試上的表現不可信。 ↩︎
來自 Hackenburg & Margetts 2024:「早期研究表明,最能力強大的 LLM 可以直接在政治問題上說服人類 (5),起起草比實際政府機構和政治傳播專家更具說服力的公共文宣 (6, 7),並生成令人信服的虛假訊息和假新聞 (1, 8, 9)。在這些領域中,人類已無法一致地辨別人類和 LLM 生成的文本 (8, 10)。」 ↩︎
維基百科上的燒貓。真的很高興那個頁面上沒有照片。(維基百科討論頁指出,關於這種特定行為的普遍程度存在學術爭論,但歷史上有很多「普通人」很可怕的例子。) ↩︎
憲法 AI:來自 AI 反饋的無害性 (2022) ↩︎
集體憲法 AI:用公眾輸入對齊語言模型 (2023) ↩︎
義務論說你應該對想找到隱藏猶太人的納粹誠實,功利主義說你應該折磨一個人來防止 10100 人眼睛進灰塵,理性利己主義會接受你走過一個容易救的溺水孩子。
但我很難想到任何在所有三個道德理論中都失敗的情況:一個行動遵守廣泛接受的規則和義務,改善他人的福祉,和你自己的福祉,但仍然「錯誤」。重點是:整合比任何單獨的理論更穩健。
(美德倫理學呢?有沒有「明智」失敗的情況?好吧,沒有,但那是因為美德倫理學極其模糊,對指導幾乎沒用。美德倫理學的大人物,亞裡士多德和阿奎那,支援奴隸制。你可以透過使用「明智」/「不明智」這些馬虎的標籤來提升/貶低任何你想要的行動。) ↩︎
使用故事教導人工代理人類價值觀,Riedl & Harrison 2016。 ↩︎
好吧,技術上沒有「這個」科學方法這回事,每個領域做的事情都略有不同,方法也在演變,但你知道我的意思。有一個「家族相似性」。「注意到東西、猜測為什麼會發生、測試你的猜測、重複」的一般過程。 ↩︎
Jan Leike 2023: 一個匯入社會價值觀的提案:用語言模型建設連貫外推意志。 ↩︎
Park 等人 2024:「我們[模擬]1,052 個真實個體的態度和行為[...] [AI 克隆]複製參與者在綜合社會調查上的回應,準確度達到參與者兩週後複製自己答案的 85%,並在預測人格特質和實驗複製結果方面表現相當。」(強調是新增的) ↩︎
連貫融合意志是在 Goertzel & Pitt 2012 中創造的:「一群多樣化人的 CBV 不應被認為是他們觀點的平均,而是[...] 將他們不同觀點的最本質元素融合成一個整體上緊湊、優雅和和諧的整體。[...] [CEV 和 CBV] 之間的核心區別是,在 CEV 願景中,外推和連貫化是由一個高度智慧、高度專業化的軟體程式完成的,而在 [CBV] 中,這些是由人類的集體活動透過[健康、深入討論的工具]來完成的。我們的觀點是,集體人類價值觀的定義可能更好地透過人類協作來進行,而不是委託給機器最佳化過程。」 ↩︎
量化前沿模型中的 CBRN 風險:「[前沿 LLM] 透過化學、生物、放射性和核(CBRN)武器知識的潛在擴散,構成前所未有的雙重用途風險。[...] 我們的發現揭露了關鍵的安全漏洞:[...] 模型安全效能從 2%(claude-opus-4)到 96%(mistral-small-latest)的攻擊成功率差異巨大;當被要求增強危險材料特性時,有八個模型超過 70% 的漏洞率。我們識別出當前安全對齊的根本脆弱性,其中簡單的提示工程技術繞過了危險 CBRN 資訊的保護措施。」 ↩︎
Spiral-Bench,一個測量 LLM 諂媚和妄想放大的基準。這個網站也託管了情商基準和廢話分數 ↩︎
衡量 AI 完成長任務的能力,METR(模型評估和威脅研究) ↩︎
Weval 是一個建立和分享你自己的 AI 評估的平臺,特別是關於被 AI 和 AI 安全社群忽視的話題,比如「哪些 AI 是基於證據的導師?」 ↩︎
洩露的 SEC 舉報人投訴挑戰 OpenAI 的非法保密協議 (2024) ↩︎
Toby Ord 2025:推理擴展重塑 AI 治理:「推理部署的快速擴展將:降低開放權重模型的重要性(以及保護閉源模型權重的重要性),減少第一個人類級別模型的影響,改變前沿 AI 的商業模式,減少對電力密集型資料中心的需求,並破壞透過訓練算力閾值進行 AI 治理的當前正規化。」 ↩︎
例如,Good Judgment Project 和 Metaculus,兩者都在一般未來事件預測方面有經過驗證的最佳記錄,分別預測本世紀先進 AI 接近滅絕風險有 1% 機率和 3% 機率。(「哦,這聽起來不太糟糕,」你想,是的,等你看到非滅絕和/或非 AI 風險的百分比吧。)此外,Metaculus 預測 AGI 的中位數(有很大不確定性)是到 2033 年,AGI 成為像農業/工業革命一樣改變物種的到 2044 年。 ↩︎
AI 增強預測:LLM 助手提高人類預測準確性 – 「參與者(N = 991)回答了一組六個預測問題,並有選項在整個過程中諮詢他們分配的 LLM 助手。我們的預先註冊的分析表明,與對照組相比,與我們每個前沿 LLM 助手互動顯著提高了 24% 到 28% 的預測準確性。探索性分析顯示一個預測專案中有一個明顯的異常值效應,排除它之後我們發現超級預測助手提高了 41% 的準確性」 ↩︎ ↩︎
Anthropic 的負責任擴展政策(2023)受美國政府生物安全級別(BSL)啟發,他們定義了 ASL-1(舊的國際象棋 AI)、ASL-2(當前 LLM)、ASL-3 ↩︎
來自 Stuart Russell,AI 最流行教科書的合著者:禁止致命自主武器:一種教育 ↩︎
引自 Tenet(2020),最「是的,這是一部諾蘭電影」的諾蘭電影。 ↩︎
例如,人類偏好的強化學習(RLHF),一種讓 AI 匯入人類價值觀的方法,就是將 Base GPT(一個自動完成工具)變成ChatGPT(一個真正的聊天機器人)的原因。同樣,提高 AI「直覺」的穩健性將有助於製造更好的 AI 醫療診斷和自動駕駛汽車。 ↩︎
天花曾經每年奪走數百萬人的生命。以下是人類如何戰勝它。,Kelsey Piper 著 ↩︎
2025 年 3 月 MIT 新聞:研究:臭氧層空洞正在癒合,感謝全球減少 CFC。「新結果以高統計置信度表明臭氧恢復進展順利。」 ↩︎
2021 年經典推文 by alex blechman ↩︎
開頭比喻來自 Nick Bostrom 2014 年的經典著作《超級智慧》 ↩︎
超級智慧代理構成災難性風險:科學家 AI 能提供更安全的路徑嗎?,Bengio 等人 2025 ↩︎
來自 Chris Olah 對 AGI 安全的看法,Evan Hubinger 著:「我們可以使用 ML 作為顯微鏡——一種學習世界的方式,而不直接在其中採取行動。也就是說,與其訓練一個 RL 代理,你可以在一堆資料上訓練一個預測模型,並使用可解釋性工具來檢查它,弄清楚它學到了什麼,然後使用這些洞察來告知——無論是有人類在迴路中還是以某種自動化方式——你實際上想在世界上採取的任何行動。」 ↩︎
分位器:有限最佳化中最大化器的更安全替代方案,Jessica Taylor 2016 ↩︎
在這裡引用我自己,呵呵:如何成為半人馬,Nicky Case (2018) 不過,見下一個腳註,主要類比現在已經過時了。 ↩︎
{kind=link}
{kind=link}